
Abstract
The Mamu-A genes of the rhesus macaque show different degrees of polymorphism, transcription level variation, and differential haplotype distribution. Per haplotype, usually one “major” transcribed gene is present, A1 (A7), in various combinations with “minor” genes, A2 to A6. In silico analysis of the physical map of a heterozygous animal revealed the presence of similar Mamu-A regions consisting of four duplication units, but with dissimilar positions of the A1 genes on both haplotypes, and in combination with different minor genes. Two microsatellites, D6S2854 and D6S2859, have been selected as potential tools to characterize this complex region. Subsequent analysis of a large breeding colony resulted in the description of highly discriminative patterns, displaying copy number variation in concert with microsatellite repeat length differences. Sequencing and segregation analyses revealed that these patterns are unique for each Mamu-A haplotype. In animals of Indian, Burmese, and Chinese origin, 19, 15, or 9 haplotypes, respectively, could be defined, illustrating the occurrence of differential block duplications and subsequent rearrangements by recombination. The haplotypes can be assigned to 12 unique combinations of genes (region configurations). Although most configurations harbor two transcribed A genes, one or three genes per haplotype are also present. Additionally, haplotypes lacking an A1 gene or with an A1 duplication appear to exist. The presence of different transcribed A genes/alleles in monkeys from various origins may have an impact on differential disease susceptibilities. The high-throughput microsatellite technique will be a valuable tool in animal selection for diverse biomedical research projects.
Similar content being viewed by others

Introduction
Gene products of the major histocompatibility complex (MHC), a multicopy gene family present in all jawed vertebrates, play a crucial role in adaptive immune responses. MHC class I molecules are involved in the binding and presentation of intracellularly generated peptides to CD8+ T cells, whereas class II molecules present peptides from extracellular origin to CD4+ T cells. The key feature of the Mhc class I and II genes is the high degree of allelic variation (polymorphism) and gene copy number variation (diversity) that is observed between as well as within species (Kelley et al. 2005). Because of its prominent role in disease susceptibility and/or resistance (Stephens 2005; Goulder and Watkins 2008; Barton and Worthington 2009; Kaur and Mehra 2009; Ramagopalan et al. 2009), transplantation biology (van Rood 1975; Doxiadis et al. 2004), reproductive success (Ziegler et al. 2005) and even stress management (Gleimer and Parham 2003), the MHC system and its polymorphisms have been extensively studied in humans (HLA; Bodmer 1987; Little and Parham 1999) and nonhuman primates such as rhesus macaques, which are often used as preclinical model species (Bontrop 2001; Carrington and Bontrop 2002; Bontrop and Watkins 2005; t Hart et al. 2005; Vierboom et al. 2005).
Equivalents of the classical HLA-A and HLA-B genes are present in rhesus macaques as well, and are designated Mamu-A and Mamu-B, whereas an ortholog of HLA-C is missing in rhesus and other macaque species (Boyson et al. 1996; Vogel et al. 1999). The Mhc class I and II gene families have been subjected to several rounds of duplications (Kulski et al. 1997, 1999; Dawkins et al. 1999) and have evolved according to birth and death processes (Klein et al. 1993; Nei et al. 1997). Thus, new genes have been created by gene duplications or complex recombination processes, whereas others have been deleted or were inactivated and became pseudogenes. Different duplication models have been proposed, of which the segmental or tandem block duplication models appear to give the most plausible explanation for the contemporary class I gene organization (Kulski et al. 1997; Dawkins et al. 1999). A tandem duplication history of 28 duplicons has been suggested for the Mamu-A region, which is indeed three times larger than in humans, and each tandem appears to contain at least one class I-like sequence, specific Alu elements, and an endogenous retroviral HERV16 segment (Kulski et al. 2004). As a consequence, on each chromosome (haplotype), more than one copy of a Mamu-A gene always seems to be present. Furthermore, the number and content of the A-genes may be different per haplotype, a phenomenon classified as region configuration polymorphism (Doxiadis et al. 2000). This phenomenon is most prominently observed for the B region of rhesus macaques, in which up to eight Mamu-B alleles are transcribed per haplotype, of which one to three show a high, the others a low transcription level. Differential transcription levels, however, are also described for Mamu-A genes (Otting et al. 2005, 2007, 2008).
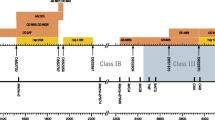
Most of the region configurations contain a polymorphic Mamu-A1 gene characterized by its high transcription level in combination with one or two oligomorphic genes designated Mamu-A2 up to Mamu-A6. In former times, the polymorphic A locus transcribed at high levels, and encoding the serotype in Indian origin rhesus macaques, was called A1. Subsequently, a second A transcript present on the same haplotype was named A2, a third A3, and so on. Furthermore, the division in loci was performed according to the clustering of alleles in phylogenetic analyses; the A2 locus alleles, for example, have a 162 bp insertion in intron 2 in common. (Otting et al. 2005). Some haplotypes contain an additional highly transcribed locus, which was named A7 according to its different phylogenetic relationship and the presence of another A1 gene on the same chromosome (Otting et al. 2007, 2009). A schematic representation illustrating the configurations of transcribed Mamu-A genes on a haplotype and its nomenclature has been provided (Fig. 1). Configuration nos. 8 to 12 (Fig. 1) have been discovered in the course of the present study and will be discussed later. One should keep in mind that nothing is known about the exact order and distances of the A genes on the genome except for configurations 1 and 5, which have been confirmed by genomic sequencing data (Daza-Vamenta et al. 2004; Shiina et al. 2006).

Schematic representation of Mamu-A region configurations observed in Indian, Chinese, and Burmese rhesus macaques. Only transcribed Mamu-A loci are represented and color-coded. The order and distances of all loci, including those of region configuration 1 and 5 of the physical map, are schematically drawn. * Region configuration 3 has not been detected in this study
In the past, products of the Mamu-A1 gene of rhesus macaques have been characterized by serological typing procedures (Bontrop et al. 1995). This method, however, is restricted to monkeys of specific, mainly Indian, origin, since adequate typing sera are missing for monkeys of different origins or from other macaque species. Until now, laborious full-length complementary deoxyribonucleic acid (cDNA) cloning and sequencing has mostly been performed for accurate typing of the polygenic Mamu-A family (Otting et al. 2007, 2009; Pendley et al. 2008; Campbell et al. 2009) or segmental analysis by pyrosequencing (Wiseman et al. 2009). Therefore, high-throughput, robust, and cost-effective typing techniques are urgently needed.
Closely linked markers, such as microsatellites, have already been successfully used for characterization of the whole MHC region (Penedo et al. 2005; Wiseman et al. 2007; Wojcechowskyj et al. 2007), the B (Bonhomme et al. 2008; Doxiadis et al. 2009b), and the DR region in different macaque and other primate species (Doxiadis et al. 2007, 2009a, 2010; de Groot et al. 2008, 2009). In a pilot study, six microsatellites mapping close to the human HLA-A gene have been tested as candidates for the characterization of the Mamu-A region, and two of them, D6S2854 and D6S2859, have been chosen because of their robustness and length variability. Since the Mamu-A loci may be duplicated on a given haplotype, a duplication of adjacent microsatellites could be expected as well and was indeed observed in the pilot study. Therefore, an in silico search of the physical map of one heterozygous rhesus monkey (Daza-Vamenta et al. 2004; Shiina et al. 2006) has been performed to identify the copy number of the markers, their position, and association with Mamu-A genes and pseudogenes. As transposable elements (TEs) such as HERV16 seem to play a role in duplication processes (Kulski et al. 2004; Doxiadis et al. 2009b), repeat masking was applied to learn more about the presence and position of TEs in relation to the localization of the two microsatellites and the Mamu-A genes/pseudogenes. Finally, a large breeding colony of rhesus macaques, covering different geographic origins, has been analyzed using the two microsatellites. The results were confirmed by full-length sequencing of Mamu-A alleles to validate the practical efficiency of this high-throughput haplotyping method.
Materials and methods
Animals and DNA/RNA isolation
The BPRC houses a self-sustaining colony of approximately 1,000 rhesus macaques mainly of Indian but also of Burmese and Chinese origin. A large collection of DNA samples as well as B-cell lines is available. For this study, genomic DNA of 819 Indian, 101 Burmese, and 14 Chinese/Indian breed rhesus macaques was analyzed. The DNA was extracted from EDTA blood samples or from immortalized B-cell lines using a standard salting-out procedure. Ribonucleic acid (RNA) was isolated from PBMCs or B cells (Rneasy kit, Qiagen, Heiden, Germany).
Mamu-A D6S2854 and D6S2859 genotyping
The polymerase chain reaction (PCR) amplification of microsatellite D6S2854, a (TAAA)n repeat, was performed under the same conditions as previously described (Wiseman et al. 2007), with the exception that the 5′ primer (D6S2854-forward-VIC: TCATGAGCGTGGCACTGCAC) is VIC labeled and the 3′ primer (D6S2854-reverse: CCGTATGTTGCAACCAGGAG) is unlabeled. D6S2859 was observed in humans as a (TA) n repeat (Gourraud et al. 2004). In rhesus macaques, it is observed as a mixed dinucleotide (TA) x (CA) y repeat, and the primers have been newly designed according to the physical map of the rhesus macaque MHC (Daza-Vamenta et al. 2004) and named D6S2859-forward-FAM: CGTTCACCCTGGCATTCCAT and D6S2859-reverse: CCCCTGATCCAGAAGCCTTG. Both primer pairs were synthesized by Applied Biosystems (Foster City, CA, USA). Both PCR reactions were multiplexed in a 25 μl reaction volume containing one unit of Taq polymerase (Invitrogen, Paisley, Scotland) with 0.3 μM of the forward and reversed primer of D6S2859, 0.1 μM of the forward and reversed primer of D6S2854, 5 mM MgCl2, 0.2 mM of each dNTP, 1×PCR buffer II (Invitrogen), and 100 ng DNA. The cycling parameters were a 5 min 94°C initial denaturation step, followed by five cycles of 1 min at 94°C, 45 s at 58°C, and 45 s at 72°C. The program was followed by 25 cycles of 45 s at 94°C, 30 s at 58°C, and 45 s at 72°C. A final extension step was performed at 72°C for 30 min. The amplified DNA was prepared for genotyping and analyzed on an ABI 3130XL genetic analyzer (Applied Biosystems). STR analysis was performed using the Genemapper software (Applied Biosystems).
cDNA cloning and sequencing
RNA was subjected to one-step reverse transcriptase (RT)-PCR as recommended by the supplier (Promega, Madison, WI, USA). The primers (5′MAS) AATTCATGGCGCCCCGAACCCTCCTCCTGG, and (3′MAS) CTAGACCACACAAGGCGGCTGTCTCAC were used, which are specific for class I A transcripts in macaques. The final elongation step was extended to 10 min to generate a 3′dA overhang. The RT-PCR products were cloned in the pDrive cloning vector using the Qiagen PCR cloning kit according to the manufacturer’s guidelines (Qiagen). After transformation in Escherichia coli-XLblue, 16 to 48 colonies were selected, and plasmid DNA was isolated using a standard mini-preparation procedure, and sequencing reactions were performed using the BigDye terminator cycle sequencing kit on an ABI 3130XL genetic analyzer (Applied Biosystems). The resulting sequences were analyzed by using the SeqMan program of the Lasergene software (DNASTAR, Madison, WI, USA) and/or MacVector™ version 10.6.0 (Oxford Molecular Group).
Nomenclature
Mamu-A alleles have been named according to established nomenclature proposals (Robinson et al. 2003; Ellis et al. 2006), which had been adapted to the recently published nomenclature for factors of the HLA system (Marsh et al. 2010). Briefly, Mamu-A1–A7 reflect the locus names, followed by an asterisk and a 3-digit or 2-digit lineage name for the A1 or A2–A7 lineages, respectively (e.g., Mamu-A1*001). A lineage is defined as a family of alleles that share a common ancestor. The lineage name is followed by the allele name, separated by a colon (e.g., Mamu-A1*001:01). If a nucleotide substitution reflects a silent mutation, this will be defined by another two digits (e.g., Mamu-A1*001:01:01). The Mamu-A haplotypes are defined by a number indicating the region configuration (Fig. 1), followed by a dot, the number of the A1 lineage, and, if needed, a letter indicating the allelic variation of one of its genes and/or variation of the microsatellite lengths: for instance, configuration 1.007a represents the haplotype of region configuration 1 with an A1*007 lineage member and the allele A1*007:01 (Table 1).
Results
Localization of microsatellites, Mamu-A genes, and TEs on the physical map
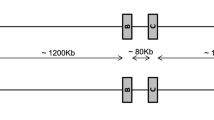
Two independent research groups published a physical map of the MHC of the same rhesus macaque. One team brought out a contig map covering the whole class I and II region of about 5.2 mb, whereas the other group mapped only the Mamu-A and Mamu-B region (Daza-Vamenta et al. 2004; Shiina et al. 2006). The rhesus macaque used for constructing the physical map is heterozygous (Daza-Vamenta et al. 2004) and the alleles of the Mamu-B (Doxiadis et al. 2009b) and Mamu-DRB genes (Doxiadis et al. 2008) had been defined. Both research groups analyzed only one haplotype for the Mamu-A region, and careful comparison suggests that they analyzed opposite haplotypes. Therefore, we tried to compare both A regions in silico by using the Mamu-SD locus which maps telomeric of the A region as a fixed anchor point (Shiina et al. 2006). On both haplotypes, four A-like genes/pseudogene can be observed centromeric from Mamu-SD (Fig. 2). Close to the SD locus, a pseudogene, named Mamu-A3 (nomenclature taken from Daza-Vamenta et al. 2004; Shiina et al. 2006), is located on both haplotypes followed by a transcribed Mamu-A1*001:01 gene on the first haplotype (Shiina et al. 2006) and A4*14:03 on the second haplotype, respectively (Daza-Vamenta et al. 2004). Furthermore, both haplotypes harbor another Mamu-70 pseudogene and a second, transcribed A gene, which corresponds to Mamu-A2*05:04 on the first and to A1*004:01:01 on the second haplotype, respectively (Fig. 2). Thus, the physical map confirmed two of the five Mamu-A region configurations (Fig. 1, region configurations 1 and 5) that were defined earlier by segregation and sequencing analyses in Indian rhesus macaques.

Detailed physical map of the Mamu-A region of a heterozygous rhesus macaque. Location of Mamu-A genes/pseudogenes, microsatellite D6S2854 and D6S2959, L1, and HERV16/HERVP71A loci are indicated in scale. Haplotype 1 is based on the pysical map of Shiina and coworkers and haplotype 2 on data of Daza-Vamenta and colleagues (Daza-Vamenta et al. 2004; Shiina et al. 2006)
One copy of the D6S2854 marker is located in close proximity to each A-like gene (Fig. 2, blue), whereas marker D6S2859 (Fig. 2, red) is present only once on these haplotypes, namely, between the Mamu-70 pseudogene and the centromeric A gene. Analysis of this 253-kb-long segment using the RepBase database (http://www.girinst.org/censor/index.php) revealed that D6S2854 is part of an AluJo(r) element, whereas D6S2859 is situated within a long HERVP71A retroviral structure. Furthermore, one long retroviral HERV16 segment maps next to the A3 pseudogene, whereas the other three A genes/pseudogenes of both haplotypes are accompanied by two HERV16 segments, one telomeric and one centromeric to the respective A locus (Fig. 2 and Table S1A, B). Additionally, the pseudogene A3 of both haplotypes and A1*001:01 or A4*14:03, respectively, as well as the A1*004:01 gene on haplotype 2 are joined by a long interspersed element, L1, that is situated next to the marker D6S2854. Thus, this part of the region harboring the classical Mamu-A genes seems to be comparable on both haplotypes (Fig. 2 and Table S1A, B), with a duplication unit characterized by one or two HERV16 elements, one Mamu-A (like) gene/pseudogene, an AluJo(r) element, and an additional L1 or HERVP71A segment. The most centromeric A gene of the first haplotype, Mamu-A2*05:02, however, misses the L1 element in contrast to its counterpart, A1*004:01 on the second haplotype. Interestingly, the Mhc region centromeric to this point on the map is totally different in both haplotypes with respect to the content of repeat elements (Fig. 2, grey shadowed).
Definition of Mamu-A haplotypes
The physical map (Fig. 2) illustrates that the microsatellite D6S2854 is part of an Alu element next to an A gene or A-like pseudogene, and D6S2859 is also localized within the part of the region that encodes for classical A gene products. Additionally, preliminary tests had shown that both markers are polymorphic in length and that the typing results were highly reproducible. Thus, both microsatellites appeared to be suitable as haplotyping reagents, and 934 monkeys of the rhesus macaque breeding colony were tested using the two markers. The animals were mainly of Indian origin, but breeding groups involving animals originating from Burma and mixed breeds of Chinese/Indian origin were also included. Genotyping with both markers resulted in patterns of various lengths (see below) that could be distributed on haplotypes by segregation analyses, since all rhesus macaques are part of well-defined breeding groups covering at least five generations. To link unambiguously the microsatellite patterns to Mamu-A haplotypes, at least one animal representing a unique haplotype was additionally characterized for its Mamu-A transcripts by full-length cDNA sequencing. This approach resulted in the definition of 19, 15, and 9 Mamu-A haplotypes for the Indian, Burmese, and Chinese origin rhesus macaques, respectively (Table 1). The haplotypes have been classified into 12 region configurations (Fig. 1) and subdivided based on the presence of different A1 lineages, according to the nomenclature described earlier. For most haplotypes, alleles of the Mamu-A1 locus have been defined plus transcripts of at least one other minor locus. As an exception to the rule that each haplotype contains one A1 locus encoding the major A transcript, there are, on the one hand, two Mamu-A haplotypes, one detected in Burmese and one in Chinese origin monkeys, without an A1 gene transcript (Table 1B, no. 11.0 and Table 1C, no. 12.0). On the other hand, one Burmese haplotype displays a duplication of the A1 locus (Fig. 1, region configuration 10; Table 1B, no. 10.043). Additionally, another Burmese haplotype is characterized by the presence of two “majors,” an A1 and an A7 (Fig. 1 region configuration 9; Table 1B, no. 9.059). The Mamu-A haplotypes no. 1.001 and 5.004a (Table 1A, B, bold) correspond to those of the physical map, which are characterized by an A1*001:01:01 allele together with an A2*05:04 (Fig. 2, haplotype 1) and A1*004:01:01 together with an A4*14:03 (Fig. 2, haplotype 2), respectively. Additionally, the microsatellite length patterns of marker D6S2854 and the length of D6S2859 of both haplotypes (Table 1A, no. 1.001 and 5.004a) correspond to those calculated from the physical map (Fig. 2). Only one marker, D6S2854-184, present in haplotype 1 (Fig. 2) cannot by detected by microsatellite analysis, most probably due to three nucleotide substitutions observed in the 3′ primer.
Microsatellite typing of the present, extended rhesus macaque panel showed a high degree of length variation of the amplicons for both markers, varying from 173 to 221 bp for D6S2854 and from 145 to 236 bp for D6S2859. Furthermore, the copy number of microsatellites present per haplotype can vary as well, namely, from zero to five for D6S2854 and from one to three for D6S2859 (Table 1). Nearly all Mamu-A haplotypes analyzed so far are characterized by unique microsatellite patterns. If two haplotypes share the same D6S2854 pattern, the lengths of D6S2859 amplicons are mostly different (e.g., Table 1A, no. 1.006a/b) and vice versa (e.g., Table 1A, no. 1.007a/b). Exceptions are rarely observed and concern haplotypes that can be differentiated by related A1 alleles if they share the same STR patterns (e.g., Table 1B no. 7.049a/b). Far more haplotypes that are characterized by the same A alleles can be subdivided by different microsatellite patterns (e.g., Table 1A no. 1.012a/b). Furthermore, one haplotype that could not be determined by Mamu-A cDNA sequencing because RNA of the respective monkey was not available could be defined by microsatellite typing as well (Table 1A). Thus, haplotyping for Mamu-A can be easily performed by this simple and robust technique using only two microsatellites.
Comparison of Mamu-A region configurations and haplotypes of different populations
In this study, most of the monkeys originated from India, and 19 Mamu-A haplotypes were distinguished (Table 1). These haplotypes belong to region configurations 1–6, most of which are characterized by the presence of one A1 gene in concert with one, sometimes two, and even no “minor” A genes. The latter configuration was described previously in cynomolgus macaques but was observed for the first time in Indian origin rhesus monkeys. In addition, five of the six configurations reported in this study have also been reported for the cynomolgus monkey (Otting et al. 2007). However, five region configurations, nos. 7–11, defined in Burmese origin monkeys, are unknown for Indian macaques (Fig. 1, Table 1 A, B). Although far fewer animals of Burmese (N = 101) than of Indian origin (N = 819) had been analyzed, the number of haplotypes (N = 15) is nearly as high.
The number of haplotypes in comparison to animals tested is most remarkable in mixed breeds of Chinese/Indian origin: in only 14 animals tested, nine Mamu-A haplotypes could be defined by segregation analysis to be of Chinese origin. Within these nine haplotypes, another novel region configuration could be described in which a bonafide A1 gene appears to be missing. In Burmese animals (Table 1 B, no. 11.0), one other region configuration was observed that seems to lack an A1 transcript. In these two haplotypes, however, the otherwise minor A gene provides the major transcript. Therefore, the number of region configurations/haplotypes will certainly increase if more rhesus macaques of Chinese origin are to be analyzed, and the number of Chinese haplotypes may then exceed those of Indian monkeys.
Most of the Mamu-A haplotypes are characterized by a specific A1 lineage member. There is, however, at least one A1 lineage, namely, A1*007, that is linked to different minor A genes, thus belonging to at least two region configurations (e.g., Table 1A no. 1.007a, b and Table 1B, no. 8.007). Additionally, this lineage is oligomorphic and present in all three macaque populations as well as in the cynomolgus monkey (Otting et al. 2009). Moreover, a few haplotypes (Table 1, no. 1007a, 5.004a, and 7.049a) are shared between monkeys of different populations, and, interestingly, haplotype 5.004a is the most frequent one in the Indian origin macaques. In most cases, however, these haplotypes are not identical but show allelic variation (indicated by letters a–e).
Discussion
The physical map of two haplotypes harboring the Mamu-A region has been compared. The content of this 253-kb-long segment within the alpha block, which is composed of four duplicons containing an A gene/A-like pseudogene and specific TEs, appears to be nearly identical in both haplotypes (Fig. 2, Table S1 A/B). This is in contrast to other parts of the Mhc of this heterozygous monkey, especially of the Mamu-B but also the Mamu-DR region (Daza-Vamenta et al. 2004; Bonhomme et al. 2008; Doxiadis et al. 2009b). Furthermore, the most centromeric part of the Mamu-A region is not identical in both haplotypes with regard to genes/pseudogenes and enclosed TEs. The haplotype variation starts from the most proximal L1 segment next to A1*004 on haplotype 2 (Fig. 2, grey shadowed). Since L1 elements are autonomous transposons, known to be responsible for genetic instability by causing insertions and deletions in mammalian genomes, this nearly intact L1 element may have been the reason for the chromosomal rearrangements observed in the past (Goodier and Kazazian 2008; Belancio et al. 2009). Although the Mamu-A region is nearly identical in the two haplotypes studied, the two major A1 genes are not on the same position of the physical map and are accompanied by different minor genes. The observation indicates that recombination-like events have taken place within the macaque alpha block after the Old World monkey-Hominoidea split about 25 million years ago (mya) (Kulski et al. 2004). This suggestion is supported by cDNA analysis as well as by microsatellite typing, which show the linkage of a certain A1 lineage (e.g., A1*007) with different minor A genes, and the existence of a haplotype with a duplication of A1 or of others that lack the A1 gene. In addition, there are haplotypes that harbor more or fewer than two transcribed Mamu-A genes. Furthermore, it is possible that others with three A genes may have remained undetected because of their low transcription levels. Another indication for the flexibility of this region is given by the microsatellite patterns that show up to five copy numbers for marker D6S2854 (Table 1). However, a lower copy number than expected may be caused by primer inconsistencies and/or the presence of different copies with the same amplicon length on one haplotype as has been shown for D6S2854-181 on the physical map (Fig. 2). Nevertheless, the copy number and length variation of both microsatellites, D6S2854 and D6S2859, appear to be highly specific for a given Mamu-A haplotype.
Six of the 12 Mamu-A region configurations have also been observed in cynomolgus monkeys and therefore seem to be old entities originating before the divergence of rhesus and cynomolgus macaques ~1.3 mya (Stevison and Kohn 2009), although a relatively recent gene flow between species is unlikely but cannot be excluded (Street et al. 2007). While region configurations may be shared between monkeys of different origin and even different species, many of the Mamu-A1 lineages, and nearly all of the allelic variations appear to be population-specific. This finding may be due to the evolutionary history of the monkeys. Macaques originated in Africa about 5 mya and expanded eastward. It is believed that rhesus macaques have their origin west of their present range, where the earliest macaque fossils are found, and then dispersed to China through an Indian wet zone. One would expect such a scenario to have led to a reduced genetic heterogeneity in Chinese origin rhesus monkeys as compared to Indian origin animals due to founder effects. This is, however, precisely the opposite of what published data show, namely, an overall higher genetic variability of Chinese- in comparison to Indian origin monkeys, proven by single nucleotide polymorphisms (SNPs) and mtDNA analysis (Smith and McDonough 2005; Ferguson et al. 2007), a greater diversity of Mhc class I sequences (Karl et al. 2008; Solomon et al. 2010) and Mamu-B haplotypes (Wiseman et al. 2009), and contrary to what can be concluded from our results presented in this study. One possible explanation may be that the lower level of genetic heterogeneity observed in Indian origin rhesus macaques reflects a severe and ancient genetic bottleneck caused by desiccation of the wet zone, which has led to the extinction of Indian origin monkeys (Smith and McDonough 2005). Furthermore, all data comparing the gene content of Chinese versus Indian origin rhesus macaques lead to the conclusion that the genetic background of Chinese and Indian origin monkeys is remarkably divergent (Smith and McDonough 2005; Ferguson et al. 2007; Otting et al. 2007, 2008; Karl et al. 2008; Wiseman et al. 2009). Additionally, a recent publication reports that about one half of the Mhc class I sequences, which the authors have defined in Burmese origin rhesus macaques, are novel, probably representing Burma origin specific class I alleles (Naruse et al. 2010). This observation is supported by our results. Thus, the genetic repertoire of rhesus macaques of different origins appears to be highly diverse. These findings may have major implications for immunologically related, preclinical studies in macaques, in which MHC class I molecules appear to play a role. Not only in humans but also in chimpanzees and macaques, there is, for example, a strong association of Mhc class I A and B alleles with a particular outcome of HIV or SIV infections (Mothe et al. 2002; O’Connor et al. 2003; Loffredo et al. 2007, 2009; Goulder and Watkins 2008; de Groot et al. 2010). Most of the studies are performed in rhesus macaques of Indian origin, and several class I molecules such as Mamu-A1*001, Mamu-B*017, and Mamu-B*008 are associated with a successful control of SIV infections (reviewed in Goulder and Watkins 2008), whereas in Burmese origin macaques, Mamu-A1*065:01 appears to be responsible for SIV control (Goulder and Watkins 2008; Tsukamoto et al. 2008), and Mamu-A1*001 has not been detected in these monkeys. Interestingly, the Mamu-A1*065:01 allele is part of the only haplotype (Table 1B, no. 10.043) that harbors two A1 alleles, and the same haplotype has also been observed by Naruse and coworkers in Burmese monkeys. Since the Mamu-A1 alleles with a high transcription level are thought to encode immunologically active molecules that present peptides to CD8+ T cells, it would be advantageous to be able to present a higher number of peptides as a “double lock strategy” after viral infections.
Recent data have shown the differential subcellular localization of some class I molecules. Strong cell surface but low intracellular expression has been detected for certain Mamu-A1-, as well as Mamu-A2-, Mamu-A3-, and Mamu-B-encoded molecules, whereas others demonstrated low surface but high intracellular expression (Rosner et al. 2010). These data indicate that not only Mamu-A1 molecules have a peptide-presenting function, and this would explain the frequent existence of haplotypes without A1 alleles, as detected in Chinese and Burmese origin macaques. Furthermore, the different MHC class I repertoires of monkeys of various origins may be one of the possible reasons that animals are more or less susceptible to diseases such as SIV/SHIV (Ling et al. 2002). Thus, our data underline the necessity to type carefully for the MHC of all animals used in preclinical, biomedical research. The high-throughput and robust STR typing method presented here can be a useful tool in achieving this aim.
Concluding remarks
The physical map of the MHC region of a heterozygous animal shows different positions of the A1 genes on both haplotypes in combination with different minor A genes. This observation suggests that recombination-like events reshaped the order of the genes within the alpha block during evolution. In addition, the existence of a total of 40 different Mamu-A haplotypes that are characterized by microsatellite copy number variation illustrates the occurrence of differential block duplications and subsequent rearrangement by recombination. The presence of different, transcribed Mamu-A genes per haplotype in monkeys of various origins may have an impact on the differential disease susceptibilities of these animals, as has been documented for the susceptibility to SIV/SHIV. Therefore, an analysis of the genetic background of monkeys prior to biomedical studies is highly recommended. The high-throughput microsatellite typing technique will be a valuable tool in animal selection for this type of study; it will also be useful in other research areas as well as in colony management, or with regard to species conservation issues.
References
Barton A, Worthington J (2009) Genetic susceptibility to rheumatoid arthritis: an emerging picture. Arthritis Rheum 61:1441–1446
Belancio VP, Deininger PL, Roy-Engel AM (2009) LINE dancing in the human genome: transposable elements and disease. Genome Med 1:97
Bodmer WF (1987) The HLA system: structure and function. J Clin Pathol 40:948–958
Bonhomme M, Doxiadis GG, Heijmans CM, Vervoort V, Otting N, Bontrop RE, Crouau-Roy B (2008) Genomic plasticity of the immune-related Mhc class I B region in macaque species. BMC Genomics 9:514
Bontrop RE (2001) Non-human primates: essential partners in biomedical research. Immunol Rev 183:5–9
Bontrop RE, Watkins DI (2005) MHC polymorphism: AIDS susceptibility in non-human primates. Trends Immunol 26:227–233
Bontrop RE, Otting N, Slierendregt BL, Lanchbury JS (1995) Evolution of major histocompatibility complex polymorphisms and T-cell receptor diversity in primates. Immunol Rev 143:33–62
Boyson JE, Shufflebotham C, Cadavid LF, Urvater JA, Knapp LA, Hughes AL, Watkins DI (1996) The MHC class I genes of the rhesus monkey. Different evolutionary histories of MHC class I and II genes in primates. J Immunol 156:4656–4665
Campbell KJ, Detmer AM, Karl JA, Wiseman RW, Blasky AJ, Hughes AL, Bimber BN, O’Connor SL, O’Connor DH (2009) Characterization of 47 MHC class I sequences in Filipino cynomolgus macaques. Immunogenetics 61:177–187
Carrington M, Bontrop RE (2002) Effects of MHC class I on HIV/SIV disease in primates. AIDS 16(Suppl 4):S105–S114
Dawkins R, Leelayuwat C, Gaudieri S, Tay G, Hui J, Cattley S, Martinez P, Kulski J (1999) Genomics of the major histocompatibility complex: haplotypes, duplication, retroviruses and disease. Immunol Rev 167:275–304
Daza-Vamenta R, Glusman G, Rowen L, Guthrie B, Geraghty DE (2004) Genetic divergence of the rhesus macaque major histocompatibility complex. Genome Res 14:1501–1515
de Groot N, Doxiadis GG, de Vos-Rouweler AJ, de Groot NG, Verschoor EJ, Bontrop RE (2008) Comparative genetics of a highly divergent DRB microsatellite in different macaque species. Immunogenetics 60:737–748
de Groot NG, Heijmans CM, de Groot N, Doxiadis GG, Otting N, Bontrop RE (2009) The chimpanzee Mhc-DRB region revisited: gene content, polymorphism, pseudogenes, and transcripts. Mol Immunol 47:381–389
de Groot NG, Heijmans CM, Zoet YM, de Ru AH, Verreck FA, van Veelen PA, Drijfhout JW, Doxiadis GG, Remarque EJ, Doxiadis II, van Rood JJ, Koning F, Bontrop RE (2010) AIDS-protective HLA-B*27/B*57 and chimpanzee MHC class I molecules target analogous conserved areas of HIV-1/SIVcpz. Proc Natl Acad Sci USA 107:15175–15180
Doxiadis GG, Otting N, de Groot NG, Noort R, Bontrop RE (2000) Unprecedented polymorphism of Mhc-DRB region configurations in rhesus macaques. J Immunol 164:3193–3199
Doxiadis II, Smits JM, Persijn GG, Frei U, Claas FH (2004) It takes six to boogie: allocating cadaver kidneys in Eurotransplant. Transplantation 77:615–617
Doxiadis GG, de Groot N, Claas FH, Doxiadis II, van Rood JJ, Bontrop RE (2007) A highly divergent microsatellite facilitating fast and accurate DRB haplotyping in humans and rhesus macaques. Proc Natl Acad Sci USA 104:8907–8912
Doxiadis GG, de Groot N, de Groot NG, Doxiadis II, Bontrop RE (2008) Reshuffling of ancient peptide binding motifs between HLA-DRB multigene family members: old wine served in new skins. Mol Immunol 45:2743–2751
Doxiadis GG, de Groot N, Dauber EM, van Eede PH, Fae I, Faner R, Fischer G, Grubic Z, Lardy NM, Mayr W, Palou E, Swelsen W, Stingl K, Doxiadis II, Bontrop RE (2009a) High resolution definition of HLA-DRB haplotypes by a simplified microsatellite typing technique. Tissue Antigens 74:486–493
Doxiadis GG, Heijmans CM, Bonhomme M, Otting N, Crouau-Roy B, Bontrop RE (2009b) Compound evolutionary history of the rhesus macaque MHC class I B region revealed by microsatellite analysis and localization of retroviral sequences. PLoS ONE 4:e4287
Doxiadis GG, de Groot N, de Groot NG, Rotmans G, de Vos-Rouweler AJ, Bontrop RE (2010) Extensive DRB region diversity in cynomolgus macaques: recombination as a driving force. Immunogenetics 62:137–147
Ellis SA, Bontrop RE, Antczak DF, Ballingall K, Davies CJ, Kaufman J, Kennedy LJ, Robinson J, Smith DM, Stear MJ, Stet RJ, Waller MJ, Walter L, Marsh SG (2006) ISAG/IUIS-VIC Comparative MHC Nomenclature Committee report, 2005. Immunogenetics 57:953–958
Ferguson B, Street SL, Wright H, Pearson C, Jia Y, Thompson SL, Allibone P, Dubay CJ, Spindel E, Norgren RB Jr (2007) Single nucleotide polymorphisms (SNPs) distinguish Indian-origin and Chinese-origin rhesus macaques (Macaca mulatta). BMC Genomics 8:43
Gleimer M, Parham P (2003) Stress management: MHC class I and class I-like molecules as reporters of cellular stress. Immunity 19:469–477
Goodier JL, Kazazian HH Jr (2008) Retrotransposons revisited: the restraint and rehabilitation of parasites. Cell 135:23–35
Goulder PJ, Watkins DI (2008) Impact of MHC class I diversity on immune control of immunodeficiency virus replication. Nat Rev Immunol 8:619–630
Gourraud PA, Mano S, Barnetche T, Carrington M, Inoko H, Cambon-Thomsen A (2004) Integration of microsatellite characteristics in the MHC region: a literature and sequence based analysis. Tissue Antigens 64:543–555
Karl JA, Wiseman RW, Campbell KJ, Blasky AJ, Hughes AL, Ferguson B, Read DS, O’Connor DH (2008) Identification of MHC class I sequences in Chinese-origin rhesus macaques. Immunogenetics 60:37–46
Kaur G, Mehra N (2009) Genetic determinants of HIV-1 infection and progression to AIDS: immune response genes. Tissue Antigens 74:373–385
Kelley J, Walter L, Trowsdale J (2005) Comparative genomics of major histocompatibility complexes. Immunogenetics 56:683–695
Klein J, O’hUigin C, Figueroa F, Mayer WE, Klein D (1993) Different modes of Mhc evolution in primates. Mol Biol Evol 10:48–59
Kulski JK, Gaudieri S, Bellgard M, Balmer L, Giles K, Inoko H, Dawkins RL (1997) The evolution of MHC diversity by segmental duplication and transposition of retroelements. J Mol Evol 45:599–609
Kulski JK, Gaudieri S, Inoko H, Dawkins RL (1999) Comparison between two human endogenous retrovirus (HERV)-rich regions within the major histocompatibility complex. J Mol Evol 48:675–683
Kulski JK, Anzai T, Shiina T, Inoko H (2004) Rhesus macaque class I duplicon structures, organization, and evolution within the alpha block of the major histocompatibility complex. Mol Biol Evol 21:2079–2091
Ling B, Veazey RS, Luckay A, Penedo C, Xu K, Lifson JD, Marx PA (2002) SIV(mac) pathogenesis in rhesus macaques of Chinese and Indian origin compared with primary HIV infections in humans. AIDS 16:1489–1496
Little AM, Parham P (1999) Polymorphism and evolution of HLA class I and II genes and molecules. Rev Immunogenet 1:105–123
Loffredo JT, Maxwell J, Qi Y, Glidden CE, Borchardt GJ, Soma T, Bean AT, Beal DR, Wilson NA, Rehrauer WM, Lifson JD, Carrington M, Watkins DI (2007) Mamu-B*08-positive macaques control simian immunodeficiency virus replication. J Virol 81:8827–8832
Loffredo JT, Sidney J, Bean AT, Beal DR, Bardet W, Wahl A, Hsawkins OE, Piaskowski S, Wilson NA, Hildebrand WH, Watkins DI, Sette A (2009) Two MHC class I molecules associated with elite control of immunodeficiency virus replication, Mamu-B*08 and HLA-B*2705, bind peptides with sequence similarity. J Immunol 182:7763–7775
Marsh SGE, Albert ED, Bodmer WF, Bontrop RE, Dupont B, Erlich HA, Fernández-Viña M, Geraghty DE, Holdsworth R, Hurley CK, Lau M, Lee KW, Mach B, Maiers M, Mayr WR, Mṻller CR, Parham P, Petersdorf EW, Sasazuki T, Strominger JL, Svejgaard A, Terasaki PI, Tiercy JM, Trowsdale J (2010) Nomenclature for factors of the HLA system, 2010. Tissue Antigens 75:291–455
Mothe BR, Horton H, Carter DK, Allen TM, Liebl ME, Skinner P, Vogel TU, Fuenger S, Vielhuber K, Rehrauer W, Wilson N, Franchini G, Altman JD, Haase A, Picker LJ, Allison DB, Watkins DI (2002) Dominance of CD8 responses specific for epitopes bound by a single major histocompatibility complex class I molecule during the acute phase of viral infection. J Virol 76:875–884
Naruse TK, Chen Z, Yanagida R, Yamashita T, Saito Y, Mori K, Akari H, Yasutomi Y, Miyazawa M, Matano T, Kimura A (2010) Diversity of MHC class I genes in Burmese-origin rhesus macaques. Immunogenetics 62:601–611
Nei M, Gu X, Sitnikova T (1997) Evolution by the birth-and-death process in multigene families of the vertebrate immune system. Proc Natl Acad Sci USA 94:7799–7806
O’Connor DH, Mothe BR, Weinfurter JT, Fuenger S, Rehrauer WM, Jing P, Rudersdorf RR, Liebl ME, Krebs K, Vasquez J, Dodds E, Loffredo J, Martin S, McDermott AB, Allen TM, Wang C, Doxiadis GG, Montefiori DC, Hughes A, Burton DR et al (2003) Major histocompatibility complex class I alleles associated with slow simian immunodeficiency virus disease progression bind epitopes recognized by dominant acute-phase cytotoxic-T-lymphocyte responses. J Virol 77:9029–9040
Otting N, Heijmans CM, Noort RC, de Groot NG, Doxiadis GG, van Rood JJ, Watkins DI, Bontrop RE (2005) Unparalleled complexity of the MHC class I region in rhesus macaques. Proc Natl Acad Sci USA 102:1626–1631
Otting N, de Vos-Rouweler AJ, Heijmans CM, de Groot NG, Doxiadis GG, Bontrop RE (2007) MHC class I A region diversity and polymorphism in macaque species. Immunogenetics 59:367–375
Otting N, Heijmans CM, van der Wiel M, de Groot NG, Doxiadis GG, Bontrop RE (2008) A snapshot of the Mamu-B genes and their allelic repertoire in rhesus macaques of Chinese origin. Immunogenetics 60:507–514
Otting N, Doxiadis GG, Bontrop RE (2009) Definition of Mafa-A and -B haplotypes in pedigreed cynomolgus macaques (Macaca fascicularis). Immunogenetics 61:745–753
Pendley CJ, Becker EA, Karl JA, Blasky AJ, Wiseman RW, Hughes AL, O’Connor SL, O’Connor DH (2008) MHC class I characterization of Indonesian cynomolgus macaques. Immunogenetics 60:339–351
Penedo MC, Bontrop RE, Heijmans CM, Otting N, Noort R, Rouweler AJ, de Groot N, de Groot NG, Ward T, Doxiadis GG (2005) Microsatellite typing of the rhesus macaque MHC region. Immunogenetics 57:198–209
Ramagopalan SV, Knight JC, Ebers GC (2009) Multiple sclerosis and the major histocompatibility complex. Curr Opin Neurol 22:219–225
Robinson J, Waller MJ, Parham P, de Groot N, Bontrop R, Kennedy LJ, Stoehr P, Marsh SG (2003) IMGT/HLA and IMGT/MHC: sequence databases for the study of the major histocompatibility complex. Nucleic Acids Res 31:311–314
Rosner C, Kruse PH, Lubke T, Walter L (2010) Rhesus macaque MHC class I molecules show differential subcellular localizations. Immunogenetics 62:149–158
Shiina T, Ota M, Shimizu S, Katsuyama Y, Hashimoto N, Takasu M, Anzai T, Kulski JK, Kikkawa E, Naruse T, Kimura N, Yanagiya K, Watanabe A, Hosomichi K, Kohara S, Iwamoto C, Umehara Y, Meyer A, Wanner V, Sano K et al (2006) Rapid evolution of major histocompatibility complex class I genes in primates generates new disease alleles in humans via hitchhiking diversity. Genetics 173:1555–1570
Smith DG, McDonough J (2005) Mitochondrial DNA variation in Chinese and Indian rhesus macaques (Macaca mulatta). Am J Primatol 65:1–25
Solomon C, Southwood S, Hoof I, Rudersdorf R, Peters B, Sidney J, Pinilla C, Marcondes MC, Ling B, Marx P, Sette A, Mothe BR (2010) The most common Chinese rhesus macaque MHC class I molecule shares peptide binding repertoire with the HLA-B7 supertype. Immunogenetics 62:451–464
Stephens HA (2005) HIV-1 diversity versus HLA class I polymorphism. Trends Immunol 26:41–47
Stevison LS, Kohn MH (2009) Divergence population genetic analysis of hybridization between rhesus and cynomolgus macaques. Mol Ecol 18:2457–2475
Street SL, Kyes RC, Grant R, Ferguson B (2007) Single nucleotide polymorphisms (SNPs) are highly conserved in rhesus (Macaca mulatta) and cynomolgus (Macaca fascicularis) macaques. BMC Genomics 8:480
t Hart BA, Bauer J, Brok HP, Amor S (2005) Non-human primate models of experimental autoimmune encephalomyelitis: variations on a theme. J Neuroimmunol 168:1–12
Tsukamoto T, Dohki S, Ueno T, Kawada M, Takeda A, Yasunami M, Naruse T, Kimura A, Takiguchi M, Matano T (2008) Determination of a major histocompatibility complex class I restricting simian immunodeficiency virus Gag241–249 epitope. AIDS 22:993–994
van Rood JJ (1975) The impact of the major histocompatibility complex on graft survival and disease susceptibility. Genetics 79(Suppl):277–291
Vierboom MP, Jonker M, Bontrop RE, t Hart B (2005) Modeling human arthritic diseases in nonhuman primates. Arthritis Res Ther 7:145–154
Vogel TU, Evans DT, Urvater JA, O’Connor DH, Hughes AL, Watkins DI (1999) Major histocompatibility complex class I genes in primates: co-evolution with pathogens. Immunol Rev 167:327–337
Wiseman RW, Wojcechowskyj JA, Greene JM, Blasky AJ, Gopon T, Soma T, Friedrich TC, O’Connor SL, O’Connor DH (2007) Simian immunodeficiency virus SIVmac239 infection of major histocompatibility complex-identical cynomolgus macaques from Mauritius. J Virol 81:349–361
Wiseman RW, Karl JA, Bimber BN, O’Leary CE, Lank SM, Tuscher JJ, Detmer AM, Bouffard P, Levenkova N, Turcotte CL, Szekeres E Jr, Wright C, Harkins T, O’Connor DH (2009) Major histocompatibility complex genotyping with massively parallel pyrosequencing. Nat Med 15:1322–1326
Wojcechowskyj JA, Yant LJ, Wiseman RW, O’Connor SL, O’Connor DH (2007) Control of simian immunodeficiency virus SIVmac239 is not predicted by inheritance of Mamu-B*17-containing haplotypes. J Virol 81:406–410
Ziegler A, Kentenich H, Uchanska-Ziegler B (2005) Female choice and the MHC. Trends Immunol 26:496–502
Acknowledgements
The authors wish to thank Donna Devine for editing the manuscript and Henk van Westbroek for preparing the figures. This study was supported in part by NIH/NIAID contract numbers HHSN266200400088C/NOI-AI-0088 and 5R24RR016038-05 (CFA:03.9389).
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Additional information
Doxiadis and Groot contributed equally to the manuscript.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Doxiadis, G.G.M., de Groot, N., Otting, N. et al. Genomic plasticity of the MHC class I A region in rhesus macaques: extensive haplotype diversity at the population level as revealed by microsatellites. Immunogenetics 63, 73–83 (2011). https://doi.org/10.1007/s00251-010-0486-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00251-010-0486-4