
Abstract
Nasopharyngeal carcinoma (NPC) is an Epstein-Barr virus (EBV)-associated malignancy with a complex tumor ecosystem. How the interplay between tumor cells, EBV, and the microenvironment contributes to NPC progression and immune evasion remains unclear. Here we performed single-cell RNA sequencing on ~104,000 cells from 19 EBV+ NPCs and 7 nonmalignant nasopharyngeal biopsies, simultaneously profiling the transcriptomes of malignant cells, EBV, stromal and immune cells. Overall, we identified global upregulation of interferon responses in the multicellular ecosystem of NPC. Notably, an epithelial–immune dual feature of malignant cells was discovered and associated with poor prognosis. Functional experiments revealed that tumor cells with this dual feature exhibited a higher capacity for tumorigenesis. Further characterization of the cellular components of the tumor microenvironment (TME) and their interactions with tumor cells revealed that the dual feature of tumor cells was positively correlated with the expression of co-inhibitory receptors on CD8+ tumor-infiltrating T cells. In addition, tumor cells with the dual feature were found to repress IFN-γ production by T cells, demonstrating their capacity for immune suppression. Our results provide new insights into the multicellular ecosystem of NPC and offer important clinical implications.
Similar content being viewed by others


Introduction
Nasopharyngeal carcinoma (NPC) is the most common head and neck cancer originating from epithelial cells in the nasopharynx and shows a high incidence throughout Southern China and Southeastern Asia.1,2 Epstein-Barr virus (EBV) is a herpesvirus that belongs to the gamma-herpesvirus family and is considered a causative factor for NPC.3,4,5 Some EBV-encoded genes contribute to the development and progression of NPC. For example, LMP1 functions in the activation of the host NF-κB, PI3K/AKT, ERK/MAPK and JAK/STAT signaling pathways, promoting cell proliferation and resistance to apoptosis.6,7,8 Much effort has been made in previous studies to understand the tumorigenesis and molecular basis of NPC, focusing on its susceptibility genes, genomic alterations and gene expression patterns (both in host and EBV), as well as host–virus interactions.9,10,11,12,13 However, these studies have largely relied on methods that investigate tumors only from a bulk perspective, limiting their power in dissecting subpopulation events such as intratumor heterogeneity (ITH) and multicellular subtypes in the tumor microenvironment (TME). To gain a deeper insight into the multicellular ecosystem of NPC, we applied single-cell RNA sequencing (scRNA-seq) to simultaneously profile the transcriptomes of malignant cells, EBV, stromal and immune cells in NPC and systematically compare the microenvironments of tumors with those of nonmalignant tissues.
Results
Single-cell transcriptomic profiling of the multicellular ecosystem of NPC
To systematically survey the cellular diversity of NPC, we performed full-length scRNA-seq on 1476 cells from 3 EBV+ NPC samples, including matched primary tumors and lymph node metastases. We also conducted 3’ droplet-based scRNA-seq (10× Genomics) on 102,525 cells from 17 EBV+ NPC and 7 non-cancerous nasopharyngeal samples (Fig. 1a; Supplementary information, Tables S1–S3). All NPC biopsies were histologically examined by H&E and EBERs staining (Supplementary information, Fig. S1a). NPC36 was studied using both scRNA-seq approaches to validate reproducibility. Quality checks of detected unique molecular identifier (UMI)/gene numbers and batch effects were performed (Supplementary information, Fig. S1b–e).

a Workflow showing the process of sample collection, single-cell dissociation, sorting, and scRNA-seq using two platforms. b t-SNE plot of all single cells from 10× Genomics. c Multi-IHC staining with anti-CD3 (T cells), anti-CD19 (B cells), anti-CD117 (mast cells), anti-Pan-CK (tumor cells), anti-CD68 (macrophages) and anti-α-SMA (fibroblasts) antibodies. Scale bar, 100 μm. d t-SNE plots comparing the distribution of single cells derived from tumors and nonmalignant tissues. e The upper panel shows large-scale CNVs of single cells from a representative tumor (NPC16) that were inferred based on scRNA-seq data. The lower panel exhibits CNVs inferred from whole-genome sequencing. f An annotated Circos plot showing the total coverage of EBV-derived sequencing reads in single cells from three tumors. EBV genes are plotted according to their position and CDS regions. Potential coexpression gene regions are linked by bands with widths proportional to the number of coexpression events among single cells.
Overall, we captured the transcriptomes of 9 major cell types according to the expression of canonical gene markers (Fig. 1b; Supplementary information, Fig. S1f) in 10× Genomics dataset. These cells included T cells, B cells, myeloid cells, mast cells, fibroblasts, endothelial cells (ECs), plasmacytoid dendritic cells (pDCs) and so on, which was consistent with the multiplex immunohistochemistry (multi-IHC) results (Fig. 1c). The cell clustering derived from tumors and nonmalignant tissues exhibited obvious differences, as exemplified by T cells, myeloid cells and fibroblasts (Fig. 1d). Using graph-based clustering, we further categorized all cells into 19 clusters (Supplementary information, Fig. S1g). Each of the 19 clusters harbored differentially expressed genes (DEGs) representing distinct cell types or subtypes (Supplementary information, Fig. S1h). To distinguish malignant from nonmalignant cells, we inferred large-scale copy number variations (CNVs) based on scRNA-seq data. Putative malignant cells were grouped together with extensive CNVs across the whole genome (Fig. 1e; Supplementary information, Fig. S1i). These inferred CNVs were highly consistent with those generated from paired bulk whole-genome sequencing, such as chromosome deletions (3p, 9p, 14q and 16q) and copy number gains (11q and 12p) (Fig. 1e; Supplementary information, Fig. S1i), which is consistent with previous reports.14,15
Among the 3 cases with full-length scRNA-seq data, we detected EBV-derived sequencing reads primarily located in the 0–6 kb and 150–170 kb regions of the EBV genome, covering virus latent genes such as LMP1, LMP2A/2B and BARTs (BARF0, A73 and RPMS1), as well as lytic genes, including LF1, LF2 and BALF3 (Fig. 1f). Interestingly, typical latent and lytic genes of EBV were co-expressed within single host cells (Supplementary information, Fig. S2a–c). Furthermore, we explored potential host–virus cross-talk in malignant cells at single-cell resolution. The expression of EBV genes BNLF2a/2b was highly correlated with host genes associated with the immune response, including C3 and CFH in NPC16, OASL and ISG20 in NPC17, and IFTM1 and SERPING1 in NPC36 (Supplementary information, Fig. S2d).
An epithelial–immune dual feature in malignant cells of NPC
We applied non-negative matrix factorization (NMF) to 10 tumors with abundant malignant cells to decipher potential programs consisting of coexpressed genes. We successfully extracted 5 programs from each tumor, generating 50 intratumor programs (Supplementary information, Table S4). The NMF result for NPC16 is shown as an example (Fig. 2a). We hypothesized that some intratumor programs reflected common features of NPC and could be merged into meta-programs. Therefore, we performed correlation clustering analysis of the 50 programs and identified two prominent meta-programs across different tumors (Fig. 2b).

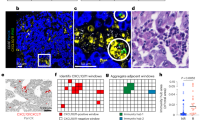
a Heatmap showing gene expression programs deciphered from a representative tumor (NPC16) using NMF. b Pearson correlation clustering of 50 intra-tumor expression programs. The dot size is proportional to the absolute value of the correlation. c The gradient of immunohistochemical staining of HLA-DRB1 in NPC tumors. Top, the strong immunoreactivity of HLA-DR in NPC59 tissue; middle, the moderate immunoreactivity of HLA-DR in NPC62 tissue; bottom, the weak immunoreactivity of HLA-DR in NPC49 tissue. pan-CK was used as a biomarker for NPC tumor cells and DAPI was used for nucleus staining. Scale bar, 10 μm. d Immunohistochemical staining with anti-HLA-DR. Scale bar, 100 μm. e Overall survival of patients with high or low HLA-DR expression. P-value was calculated by the log-rank test. f Progression-free survival of patients with different ISs inferred from bulk RNA-seq data. P-value was calculated by the multivariate Cox regression test. g Comparison of cell survival between IS-high and IS-low populations from a C17 NPC xenograft by the CCK-8 assay. IS-high, EpCAM+HLA-DRhi; IS-low, EpCAM+HLA-DRlow. h, i Comparison of tumor weight and size in nude mice generated from IS-high and IS-low populations injected into a C17 NPC xenograft. Data are means ± SEM. IS-high, EpCAM+HLA-DRhi; IS-low, EpCAM+HLA-DRlow.
One meta-program was characterized by expression of cell cycle-related genes like CDK1 and MCM2 (Fig. 2a, b; Supplementary information, Table S4). Unexpectedly, the other remarkable meta-program was characterized by the expression of immune-related genes on tumor cells (Fig. 2b). We defined this meta-program using 36 genes selected from intratumor immune programs (Supplementary information, Table S5), which included interferon (IFN)-response genes (e.g., IFN-stimulated gene 15 (ISG15)), major histocompatibility complex II (MHC II)-coding genes (e.g., HLA-DPA1) and complement genes (e.g., C3). We then calculated an immune score (IS) for malignant cells depending on the expression of the 36 selected genes and ranked cells by the IS. A significant gradient of IS was observed within each tumor, demonstrating a pronounced ITH of this meta-program (Supplementary information, Fig. S3a). We then calculated an epithelial score for each cell and examined its correlation with the IS among single cells. Malignant and nonmalignant cells could be clearly separated based on epithelial scores. In contrast, a fraction of malignant cells could not be separated from nonmalignant cells based on the IS (Supplementary information, Fig. S3b). These malignant cells displayed a high IS that was similar to that of nonmalignant cells (mostly immune cells), thus possessing an epithelial–immune dual feature (Supplementary information, Fig. S3c). To further validate this dual feature, we performed multi-IHC, immunofluorescence (IF) staining and flow cytometry on additional NPC samples, and we observed coexpression of epithelial markers (e.g., pan-CK or EpCAM) and HLA-DR in single malignant cells (Fig. 2c; Supplementary information, Fig. S3d, e).
Next, we sought to understand what consequences were associated with the dual feature. Notably, we found that IFN response and signaling-associated genes were significantly enriched in cells with a high IS (Supplementary information, Fig. S4a). On the other hand, we found that the IS-correlated genes widely overlapped with a list of genes (e.g., STAT1, ISG15 and IFIT1) potentially related to DNA damage resistance and chemotherapy/radiotherapy resistance16 (Supplementary information, Fig. S4b). Given that the primary treatment strategy for NPC is radiotherapy, we speculated that the dual feature of malignant cells might lead to a dismal prognosis for NPC patients. To test the correlation between the dual feature and prognosis, we examined the expression of HLA-DR in an additional patient cohort (n = 95) using IHC staining (Fig. 2d; Supplementary information, Table S6). Patients with higher expression of HLA-DR on tumor cells had decreased overall survival (OS) (log rank test, P = 0.026) (Fig. 2d, e), indicating that the dual feature was closely associated with prognosis. This correlation was also confirmed by analyzing NPC bulk RNA-seq data (n = 111) (Fig. 2f).
Furthermore, we sorted tumor cells into IS-high (EpCAM+HLA-DRhi) and IS-low (EpCAM+HLA-DRlow) subgroups from the C17 PDX mouse model based on the expression of HLA-DR and investigated their functional differences. In an in vitro culturing experiment, IS-high tumor cells presented larger cell numbers compared to IS-low tumor cells as measured by the CCK-8 assay (Fig. 2g; Supplementary information, Fig. S4c). Moreover, when sorted IS-high or IS-low tumor cells were injected into nude mice, IS-high tumor cells generated tumor burdens larger than those produced by IS-low tumor cells. These findings indicate that IS-high tumor cells possess a stronger capacity for tumorigenesis (Fig. 2h, i; Supplementary information, Fig. S4d), which may also explain why the dual feature on tumor cells was associated with a poor prognosis. Notably, tumors grown from IS-high tumor cells were found to maintain high HLA-DR expression, and vice versa (Supplementary information, Fig. S4e).
T cell clustering and state analysis in NPC
We analyzed the gene expression of 33,895 T cells from both tumors (18,931 T cells) and nonmalignant tissues (14,964 T cells) (Supplementary information, Fig. S5a). We categorized all cells into 13 clusters, which exemplified the functional heterogeneity of the T cell population (Fig. 3a; Supplementary information, Fig. S5a and Table S7). We further surveyed the expression and distribution of canonical T cell markers among the 13 clusters (Fig. 3b, c; Supplementary information, Fig. S5b).

a t-SNE plot showing 13 clusters of 33,895T cells. b Expression and distribution of canonical T cell marker genes among cells. Red to gray: high to low expression. c Average expression of T cell-specific markers across different clusters. The dot size is proportional to the relative expression level of each gene. d T cell distributions from tumors and nonmalignant tissues. e Scatterplot showing DEGs in tumor-derived CD8+ and CD4+ T cells in comparison with those derived from nonmalignant tissues. Representative genes are labeled. f Volcano plot showing DEGs in tumor-derived cytotoxic T cells in comparison with those derived from nonmalignant tissues. Representative genes are labeled. g The developmental trajectory of CD8+ T cells inferred by Monocle2. h 2D density plot of the cytotoxicity and exhaustion states of CD8+ T cells. Cells are partitioned into ‘high cytotoxicity & high exhaustion’ (CyhighExhigh) and ‘high cytotoxicity & low exhaustion’ (CyhighExlow) groups. i Scatterplot shows DEGs (red dots) between the CyhighExhigh and CyhighExlow groups.
The distribution of T cells derived from tumors and nonmalignant tissues was dichotomic (Fig. 3d). Cluster C4 represented regulatory T cells (Tregs) with high expression levels of FOXP3, IL2RA and IKZF2 (Fig. 3c). Cells in C4 were dominantly tumor-derived (Supplementary information, Fig. S5c), indicating that the immune microenvironment in NPC was skewed towards a more tolerogenic milieu. Cells in C5 showed high expression levels of PDCD1 and CXCL13 (Fig. 3b, c), thus representing follicular T helper cells involved in the formation of ectopic lymphoid-like structures in inflammatory sites.16 T cells from C2, C7 and C9 showed high expression levels of cytotoxic markers such as NKG7 and GZMK (Fig. 3c). Interestingly, C2, C7 and C9 exhibited variable expression of exhaustion markers (Fig. 3c), indicating an activation-coupled exhaustion program. Unlike naïve CD8+ T cells, most cytotoxic CD8+ T cells were derived from tumors (Supplementary information, Fig. S5c). This finding shows that tumor-infiltrating T cells in NPC were highly activated and exhausted, putatively by both tumor cells and EBV infection.
Compared with nonmalignant tissues, the gene expression results of tumor-derived CD4+ and CD8+ T cells, showed enrichment in similar pathways, among which IFN response-related pathways ranked high in both groups (Supplementary information, Fig. S5d). Meanwhile, enrichment in glycolysis of both CD4+ and CD8+ T cells reflected a common metabolic adaptation to the tumor (Supplementary information, Fig. S5d). In comparison with nonmalignant tissues, co-stimulatory and co-inhibitory receptors such as TNFRSF9 and TIGIT, as well as chemokine receptors such as CXCR3 and CXCR6, were upregulated in both tumor-derived CD4+ and CD8+ T cells (Fig. 3e). Next, we compared the expression profiles of tumor-derived and nonmalignant tissue-derived cytotoxic CD8+ T cells, Tregs and natural killer (NK) cells (Fig. 3f; Supplementary information, Fig. S5e, f and Table S7). Cytotoxic CD8+ T cells in tumors showed higher expression levels of cytotoxicity-related genes GZMB and GZMH, immune regulator ZNF683, chemokine CXCL13, and exhaustion markers LAG3 and HAVCR2 (Fig. 3f). Interestingly, tumor-derived Tregs showed a higher expression level of LGALS1 (Supplementary information, Fig. S5e), which was reported to mediate immunosuppression of CD8+ T cells in EBV+ Hodgkin lymphoma.17 This finding suggests that tumor-derived Tregs harbored higher immunosuppressive capacity, which was potentially associated with EBV infection.18 Meanwhile, tumor-derived Tregs also showed higher expression of SOX4 (Supplementary information, Fig. S5e), which may be related to conversion between Tregs and T helper cells.
Finally, we constructed a developmental trajectory of CD8+ T cells and calculated a cytotoxicity score and exhaustion score for each cell based on the expression of canonical markers (Fig. 3g; Supplementary information, Fig. S5g). Along the trajectory, T cells exhibited gradually increasing cytotoxic activity, which was accompanied by gradually increasing exhaustion (Supplementary information, Fig. S5g, h). Although most CD8+ T cells followed the trend of activation-coupled exhaustion, a subset exhibited high cytotoxicity but low exhaustion status (Fig. 3h). By comparing the DEGs between the two groups (Supplementary information, Table S7), we found that well-known exhaustion markers, such as PDCD1, LAG3, TIGIT and HAVCR2, were significantly upregulated in the CyhighExhigh group. Notably, we also identified potential novel exhaustion markers, including VCAM1, PTMS and TIMD4 (Fig. 3i).
Myeloid and stromal cell clustering and state analysis in NPC
We analyzed the transcriptomes of 6053 myeloid cells, including 4646 tumor-derived cells and 1407 nonmalignant tissue-derived cells. Myeloid cells exhibited remarkable heterogeneity and were categorized into 12 clusters (Fig. 4a; Supplementary information, Table S8). We annotated these clusters based on the expression of canonical markers and their tissue origins (Supplementary information, Fig. S6a, b). Cluster C2 highly expressed the IGJ gene, thus representing pDCs. Cluster C8 was tumor-specific and corresponded to Langerhans cells because of its high expression of FCER1A. Cluster C9 specifically expressed CCR7 and represented migratory DCs (Fig. 4a, b; Supplementary information, Fig. S6a, b). Clusters C3, C4, C5 and C6 represented monocytes/macrophages, as indicated by genes such as CD14, CD163 and CQ1B (Supplementary information, Fig. S6a). We constructed a diffusion map to depict the developmental trajectory of myeloid cells (Fig. 4b). The diffusion map of monocytes/macrophages (clusters C3, C4, C5 and C6) revealed two developmental paths, possibly corresponding to the classical M1 and M2 phenotypes. Intriguingly, cluster C3, which corresponded to path 1, contained upregulated genes and pathways associated with the M1 phenotype, such as CXCL9 and reactive oxygen species signaling. Cluster C3 also exhibited typical M2 phenotypes, such as high expression of MMP9 and CCL13 and reduction of the inflammatory response (Supplementary information, Fig. S6c–e). We calculated an M1 score and M2 score for each cell based on previously reported markers.19 Strikingly, we found that the M1 and M2 signatures were positively correlated among the 4 monocyte/macrophage clusters (Fig. 4c). This result indicates that macrophage activation in the TME may follow different patterns, such as M1–M2 coupled activation.

a t-SNE plot showing 12 clusters of myeloid cells. b 3D diffusion map displaying the developmental trajectory of myeloid cells. The magnified section shows the possible activation paths of macrophages. Cells are colored by their derived clusters. pDCs, plasmacytoid dendritic cells; cpDCs, cross-presenting dendritic cells; mDCs, myeloid-derived dendritic cells. c Scatterplot showing the correlation between the M1 and M2 scores. d t-SNE plot showing 7 clusters of fibroblasts. e Violin plots showing the expression levels of different marker genes across 7 fibroblast clusters. f 3D diffusion map displaying the developmental trajectory of different clusters of fibroblasts. The dashed circle highlights cells that may bridge CAFs and myofibroblasts. g Comparison of IFN-α and IFN-γ scores of single cells in various cellular components of the TME between NPCs and nonmalignant tissues.
Furthermore, we compared the gene expression profiles of myeloid cells derived from tumors and nonmalignant tissues (Supplementary information, Fig. S6f). Similar to the observations in T cells, IFN response-related pathways were upregulated in both tumor-derived DCs and macrophages (Supplementary information, Fig. S6g). Tumor-derived macrophages also showed upregulated inflammatory response-associated genes (e.g., CCL2 and IL8) (Supplementary information, Fig. S6f and Table S8). This finding was different from previous results in lung cancer, where tumor-derived macrophages largely downregulated the pro-inflammatory signature.20 The special adaptation of macrophages to NPC may be associated with chronic EBV infection, which may trigger and maintain a high level of inflammatory response in the TME.
We also captured the transcriptomes of 1416 fibroblasts, including 1195 derived from tumors and 221 derived from nonmalignant tissues (Fig. 4d; Supplementary information, Fig. S7a). Using graph-based clustering, we identified 7 clusters of fibroblasts (Fig. 4d; Supplementary information, Table S8). Clusters C3 and C6 displayed high expression levels of ACTA2, MCAM and MYLK, thus representing myofibroblasts (Fig. 4e; Supplementary information, Fig. S7b). On the other hand, clusters C2 and C5 corresponded to cancer-associated fibroblasts (CAFs) that highly expressed genes such as FAP, PDPN and MMP11 (Fig. 4e; Supplementary information, Fig. S7b). Notably, cluster C5 specifically expressed immunosuppressive factor IDO1 (Fig. 4e), demonstrating its role in immunosuppression of T cells. Remarkably, some collagens such as COL1A2 and COL6A1 were ubiquitously expressed by all 7 clusters despite with variable expression levels, while some collagens, like COL4A1, were expressed by several, but not all, clusters. In contrast, some collagens, like COL11A1, were expressed solely by one cluster (Fig. 4e). The heterogeneous pattern of collagen production may fulfill the functional diversity of fibroblasts in the TME.
Additionally, the developmental trajectory of fibroblasts showed that the lineages of myofibroblasts and CAFs were different (Fig. 4f). We compared the gene expression of fibroblasts derived from tumors and nonmalignant tissues. Significantly, upregulated genes in tumor-derived fibroblasts were enriched in IFN response-related pathways (Supplementary information, Fig. S7d, e and Table S8). Additionally, we also investigated the gene expression of the EC population (Supplementary information, Fig. S8).
Global IFN response in the multicellular ecosystem of NPC
Compared with nonmalignant tissues, IFN responses were significantly upregulated in tumor-derived T cells (both CD4+ and CD8+), DCs, macrophages, fibroblasts and endothelium (Fig. 3e; Supplementary information, Figs. S5d, S6g, S7e, S8e). This finding prompted us to investigate whether it was a prevailing feature in the TME of NPC. We then calculated and compared the IFN-α and IFN-γ scores within each of the major cell types between tumor-derived and nonmalignant tissue-derived cells. Indeed, we found that major cell types in NPC had significantly higher IFN-α and IFN-γ scores, demonstrating global upregulation of the IFN response in the TME of NPC (Fig. 4g). This feature has not been reported in other cancer types (e.g., lung cancer) and may reflect the role of viral infection in shaping the TME.
TME compositions and cell–cell interactions in NPC
Based on cell type-specific markers extracted from scRNA-seq data (Supplementary information, Table S9), we profiled the expression patterns of these markers in bulk RNA-seq. The gene expression profiles of 140 primary NPC tumors from treatment-naïve patients were analyzed and partitioned into 5 groups (G1–G5) according to their notable differences in TME compositions (Fig. 5a; Supplementary information, Fig. S9a). Tumors in G4 and G5 exhibited relatively lower immune cell-associated signature, while tumors in G5 had a higher expression of the fibroblast-associated signature. Tumors in G1, G2 and G3 had relatively higher abundance of immune cells. In particular, tumors in G3 contained more B cells, whereas tumors in G2 had a remarkably higher fraction of fibroblasts (Fig. 5a). To validate the TME stratification based on RNA-seq data, we preformed multi-IHC staining of different immune and stromal cells in additional NPC samples (Fig. 5b). We also examined the clinical records of these patients and found that patients assigned to the 5 groups exhibited different progression-free survival (PFS) (Fig. 5c).

a Heatmap showing the relative expression levels of cell type-specific genes in 140 NPC bulk expression profiles. b Multi-IHC staining in NPC TME. Staining with anti-CD3 (T cells), anti-CD19 (B cells), anti-CD117 (mast cells), anti-Pan-CK (tumor cells), anti-CD68 (macrophages) and anti-α-SMA (fibroblasts) antibodies in two representative tumors. Scale bar, 100 μm. c Progression-free survival of patients with different TME compositions. P-values were calculated by the log-rank test. d, e Circos plots displaying putative ligand–receptor interactions between tumor cells and nonmalignant cells. Interactions are divided into incoming and outgoing events. The brand links pairs of interacting cell types, and its width is proportional to the number of events, which is also labeled in the graph. Representative ligand–receptor pairs are labeled. f, g Scatterplots depicting inferred cell–cell interactions between fibroblasts and ECs (f), tumor cells and T cells (g). h Summary of selected ligand–receptor interactions between different cell types. P–values (permutation test) are represented by the size of each circle. The color gradient indicates the level of interaction. Black triangles indicate that the interacting cell types are derived from nonmalignant tissues.
To assess cell–cell interactions in the TME of NPC, we first investigated the expression of various ligand–receptor pairs among single cells. Most incoming events for tumor cells were mediated by fibroblasts, as fibroblasts expressed a notably higher number of valid ligands whose receptors were expressed by tumor cells (P < 0.01) (Fig. 5d; Supplementary information, Fig. S9b). These events included typical ECM–receptor interactions such as COL1A1–ITGB1 and COL6A1–ITGB1, which potentially promoted tumor progression. Additionally, fibroblasts mediated most interactions with other cell types in the TME (Supplementary information, Fig. S9c). With regard to outgoing events, NPC tumor cells exhibited notable chemoattraction for T cells through interactions such as CXCL10–CXCR3 and CXCL16–CXCR6 (Fig. 5e). Combining single-cell transcriptomes with bulk RNA-seq, we pinpointed genes that were predominantly expressed in one cell type, but were correlated with the abundance of other cell types. For example, COL6A3, COL14A1 and CD248 were highly expressed by fibroblasts and positively correlated with EC abundance in the TME (Fig. 5f), implying their potential roles in EC recruitment and angiogenesis. Complement genes such as C2, C3 and SERPING1, which were expressed by fibroblasts, were highly correlated with T cell abundance (Supplementary information, Fig. S9d). Similar results were reported in melanoma.21 However, unlike melanoma, complement genes such as C1S, C3, CFH, and CFB were also widely expressed by tumor cells in NPC and correlated with T cell abundance (Fig. 5g; Supplementary information, Fig. S9e).
Finally, we investigated specific ligand–receptor interactions between different cell types in the TME and the nonmalignant microenvironment (Fig. 5h). We identified immune inhibitory interactions between tumor cells and T cells, including PDL1–PD1, PVR–TIGIT and LGALS9–TIM3. These interactions may mediate tumor cell immune escape despite heavy lymphocyte infiltration. In particular, LGALS9–TIM3 interaction has been implicated in Treg expansion and cytotoxic T cell (Tcyto) apoptosis following viral infection; this observation hints towards EBV-regulated immunosuppression. Besides, recruitment of T cells by tumor cells via complement factors was also observed (e.g., C3–C3AR1). Interestingly, compared with nonmalignant tissue-derived ECs, tumor-derived ECs showed an enhanced capacity to attract Tcytos and Tregs (e.g., CXCL9–CXCR3 and CXCL10–CXCR3), but they simultaneously inhibited the activity of Tcytos through PDL2–PD1 interaction. In addition, tumor-derived macrophages showed decreased chemokine–receptor interactions with Tcytos and Tregs, including CXCL12–CXCR3 and CXCL12–CXCR4, while they showed enhanced CD86–CTLA4 interaction.
Immune modulation and suppression of dual-feature tumor cells
We next compared the interactions between IS-high/IS-low tumor cells and tumor-infiltrating lymphocytes (TILs). Interestingly, in comparison to IS-low tumor cells, IS-high tumor cells exhibited stronger ligand–receptor interactions such as CXCL11–CXCR3, C3–IFITM1, and PDL1–PD1 towards T cells, demonstrating that IS-high tumor cells have greater potential for immune recruitment, modulation and suppression (Fig. 6a). Using fluorescence-activated cell sorting (FACS) on additional NPC tissues, we detected the expression of co-inhibitory receptors (e.g., PD-1, LAG-3, TIM-3, TIM-4, and CD276) on TILs and found their expression on CD8+ TILs were positively correlated with the abundance of IS-high tumor cells in the same NPC tissues (Fig. 6b).

a Summary of selected ligand–receptor interactions between subgroups of tumor cells with T cell types. P-values (permutation test) are represented by the size of each circle. The color gradient indicates the level of interaction. Black triangles indicate that the interacting cell types were derived from nonmalignant tissues. b Correlation of inhibitory receptors expression in the infiltrating tumor CD8+ T cell subgroup with the percentage of EpCAM+HLA-DRhi tumor cells from NPC tissues (n = 27). c Comparison of co-expression of inhibitory receptors in CD8+ T cells between EpCAM+HLA-DRhi and EpCAM+HLA-DRlow subgroups of NPC samples (n = 27, EpCAM+HLA-DRhi and EpCAM+HLA-DRlow subgroups were defined using the median expression of HLA-DR). d, e Quantification of IFN-γ production by the ELISPOT assay after co-culturing of TILs with a panel of IS-high (EpCAM+HLA-DRhi) and IS-low (EpCAM+HLA-DRlow) tumor cells with particular degradant ratios (TILs:tumor cells, 100:1, 50:1, 20:1). f Comparison of co-inhibitory receptor expression in CD8+ T cells after co-culturing with EpCAM+HLA-DRhi or EpCAM+HLA-DRlow tumor cells (TILs:tumor cells, 100:1).
In addition, we found that the dual feature of tumors was associated with co-expression of co-inhibitory receptors in CD8+ T cells, such as TIM-3/PD-1, LAG-3/PD-1, and CD276/PD-1, reflecting a deeper dysfunction of CD8+ TILs (Fig. 6c; Supplementary information, Fig. S10a, b). To further explore the immune-modulatory function of IS-high tumor cells, we co-cultured IS-high/IS-low tumor cells (from TW03-EBV+ cell line) with TILs isolated from NPC tissues (with matched HLA-A2 subtyping). The TILs isolated from NPC tissues were first allowed to expand for 7–14 days to reach enough cell numbers.22,23 Notably, TILs co-cultured with IS-high tumor cells produced less IFN-γ as measured by the ELISPOT assay (Fig. 6d, e). This finding indicated that IS-high tumor cells had greater capacity for immune suppression. By co-culturing tumor cells with TILs, we found that IS-high tumor cells induced a higher proportion of CD8+ TILs with co-inhibitory receptor expression in comparison with IS-low tumor cells (Fig. 6f; Supplementary information, Fig. S10c), suggesting that IS-high tumor cells may trigger a deeper dysfunction of CD8+ T cells. Taken together, the ability of the IS-high tumor cells to induce immune suppression may also contribute to the association between the dual feature of tumor cells and poor prognosis.
Discussion
Our study integrated large-scale single-cell transcriptomes with bulk RNA-seq data for a comprehensive profiling of the multicellular ecosystem in EBV+ NPC, portraying the complex interplay among EBV, tumors and the microenvironment.
The epithelial–immune dual feature of tumor cells in NPC is mainly characterized by the expression of IFN response genes. In our study, we found that MHC II genes were widely expressed on tumor cells. MHC II members, which are usually expressed on professional antigen-presenting cells (e.g., DCs, macrophages), can be expressed on epithelial cells upon IFN-γ induction.24 It has also been reported that MHC II can be expressed on epithelial cells of the gut/respiratory tract.25 MHC II molecules expressed on epithelial cells are able to interact with CD8+ T cells,26,27 as well as CD4+ T cells. The roles of MHC II molecules in cancer seem contradictory and remain an open question. Accumulating evidence demonstrates that tumor-specific MHC II expression associates with favorable outcomes in many cancer types (e.g., breast cancer,28,29 colon cancer,30 melanoma31). However, an opposite function for MHC II has also been reported. HLA-DR+ melanoma educed CD8+ T cell activities by inducing LAG3+ and FCRL6+ TILs32 or recruiting more tumor-specific CD4+ T cells.33 The absence of MHC II molecules in the TC-1 mouse model of HPV-related carcinoma led to CD8+ T cell infiltration and activation, contributing to tumor rejection rather than tumor progression.34
In our study, we explored the role of MHC II molecules in NPC. First, HLA-DRhi tumor cells have a stronger tumorigenic ability. Second, the expression of HLA-DR in tumor cells of NPC samples is positively correlated with the expression of co-inhibitory immune receptors, such as PD-1, LAG-3, TIM-3, TIM-4, and CD276 on tumor-infiltrating T cells. Due to a lack of immune competent animal model for nasopharyngeal carcinoma, we applied the co-culture experiment to investigate the interaction between NPC tumor cells and HLA partially-matched TILs. Our data suggest that tumor cells with strong MHC II expression might directly or indirectly interact with CD8+ T cells and enhance CD8+ T cell exhaustion, promoting tumor progression in NPC. Meanwhile, we used the nude mice xenograft model to study the tumor growth ability of IS-high tumor cells. Our results demonstrate that IS-high tumor cells presented a stronger proliferation capacity in the immune-defective mice, suggesting that the IS-high tumor cells, themselves, have an enhanced tumorigenesis ability. ISG15 was one of the IS genes. We also assessed the expression level of ISG15 on tumor cells using IHC and the results confirmed a variable expression, similar to the pattern of HLA-DR.35 Furthermore, the high expression of ISG15 was correlated with more frequent local recurrence and shorter overall survival in NPC patients.35 Our findings suggest that the ISs of tumor cells can serve as a potential biomarker for predicting the prognosis of NPC patients.
Although the role of IFN response in defeating viral infection is well established, the IFN pathway also plays important roles in the dysfunctional immune states associated with chronic viral infection and cancer.36 We hypothesize that the dismal prognosis of patients with high IS in our study partially results from the immune suppression ability conferred upon the tumor cells by the IFN response. Therefore, we speculate that the IFN response functions as a ‘double-edged sword’ in NPC; while its original function is to combat viral infection, a sustained IFN response in epithelial cells after malignant transformation facilitates tumor cell survival within a suppressed tumor microenvironment.
In terms of T cell function states in NPC, it will be interesting to reveal to what extent the exhaustion state of T cells is caused by chronic EBV infection instead of tumor cells in NPC. Nonetheless, cytotoxic CD8+ T cells widely express immune checkpoint factors (e.g., PDCD1 and LAG3), which necessitates the use of immune checkpoint blockage in NPC.37 Our scRNA-seq profiling of T cell functional states provides the foundation for on-going/future immunotherapy in NPC patients. In contrast with classic M1 and M2 polarization models, macrophage activation in NPC follows an M1–M2 coupled pattern, in which M1 and M2 are not discrete states, but coupled programs. This was also reported previously in pancreatic cancer.38 Both pro-inflammatory and pro-tumoral signatures are exhibited by macrophages. This seemingly paradoxical activation may be associated with chronic EBV infection, which can cause long-lasting inflammatory responses in the TME. As an alternative form of molecular subtyping, stratification based on TME can serve as an indicator that is closely associated with treatment response and patient prognosis.
Materials and methods
NPC samples and nonmalignant nasopharyngeal tissues
This study was approved by the institutional review board of the Sun Yat-Sen University Cancer Center (SYSUCC). All patients provided informed consent preoperatively and received no treatment before biopsy. All biopsies were obtained either from patients diagnosed with EBV+ NPC or from nasopharyngeal biopsies under nasopharyngeal endoscope acquired from patients suspected of having NPC. For scRNA-seq, in total, we collected primary tumors or lymph node metastases from 19 EBV+ NPC patients, and 7 non-cancerous nasopharyngeal samples from normal subjects (Supplementary information, Table S1).
Tumor dissociation
Fresh tumors were collected in RPMI-1640 (Gibco, Cat# 11879020) on ice at the time of resection. To harvest highly viable cells, single cells were isolated within 2.5 h after sample collection. The biopsy tissues were mechanically resected into tiny cubes (~1–2 mm3) and enzymatically dissociated in 5 mL PBS (Invitrogen, Cat# C10010500BT) with 100 μg/mL LiberaseTM Research Grade (Roche, Cat# 5401127001) and 5 U/μL DNase I (NEB, Cat# M0303L) for 20 min at 37 °C. The dissociation process was conducted in a shaking incubator at 50 rpm. Large clumps and cell debris were removed using a 70-μm filter, after which the filtered cells were gently added to a tube containing a density gradient of 5 mL Lympholyte-H (Cedar Lane labs, Cat# CL5020) to remove red blood cells and debris according to the manufacturer’s recommendations. Finally, the single cell suspension was used for staining and flow cytometry.
Single-cell isolation, cDNA amplification and library construction
Single-cell suspensions were stained with antibodies against 7-AAD (BD Pharmingen, Cat# 559925), Calcein blue AM (Invitrogen, Cat# C1429) and EpCAM (Abcam, Cat# ab112068) for FACS using a MoFlo Astrios (Beckman Coulter). To discriminate single cells from doublets, standard forward scatter height (FSH) versus areas (FSA) and side scatter height (SSH) versus width (SSW) were used. To acquire viable cells, 7-AAD– Calcein-blue-AM+ populations were gated. For full-length Smart-seq2, single cells were sorted into 96-well plates containing cell lysis buffer.35 EpCAM+ and EpCAM– single cells were sorted within the gates of 7-AAD–Calcein-Blue-AM+EpCAM+ and 7-AAD–Calcein-Blue-AM+EpCAM–, respectively. Next, the plates were tightly sealed and centrifuged at 2000 rpm for 1 min at 4 °C. The plates were stored immediately at −80 °C. For the droplet-based scRNA-seq, EpCAM+/EpCAM– cells (with a ratio from 1:10 to 1:1) were enriched in PCR tubes containing 5 μL 1% FBS (Gibco, Cat# 10099133)-PBS and later mixed with EpCAM– cells. The cell suspension was stored on ice. Before proceeding to the 10× Genomics GemCode platform, the cell count and cell viability were measured using a Neubauer improved cell counter plate.
The Smart-seq2 protocol was performed on single sorted cells as described previously with some modifications.39 In brief, full-length cDNA was synthesized by the template-switching reaction using the Superscript II reverse transcriptase (Invitrogen, Cat# 18064014). cDNA was amplified using KAPA HiFi HotStartReadyMix (KAPA Biosystems, Cat# KM2602). The cDNA libraries were barcoded and constructed using the TruePre DNA Library Prep Kit V2 kit (Vazyme, Cat# TD503–02). For 3’ droplet-based single-cell library construction, we loaded an expected number of cells into the chip to generate gel beads-in-emulsion (GEMs). After post GEM-RT cleanup and cDNA amplification, 3’ droplet-based single-cell libraries were constructed according to the Single Cell 3’ Reagent Kit V2 User Guide (10× Genomic).
Bulk DNA and RNA isolation and sequencing
DNA was isolated from the NPC biopsies using the QIAamp DNA Mini Kit (QIAGEN) following the manufacturer’s recommendations. Whole-genome sequencing libraries were constructed using the TruePre DNA Library Prep Kit V2 (Vazyme, Cat# TD501–02) for Illumina according to the manufacturer’s specifications. Library quantification was measured by a high sensitivity dsDNA Quant Kit (Invitrogen, Cat# Q32854). Quality analysis was performed using High Sensitivity NGS Fragment Analysis Kit (AATI, Cat# DNF-474) by Fragment Analyzer (AATI). All samples were sequenced using the Illumina HiSeq X Ten platform to generate 150-bp paired-end reads (sequenced by Annoroad).
For bulk RNA-seq, additional 18 NPC specimens (Supplementary information, Table S10) obtained from SYSUCC were subjected to total RNA isolation using a commercial RNA extraction kit (Omega). After whole transcriptome amplification, library construction was performed using the Truseq RNA Library Prep kit v2 (Illumina) following the manufacturer’s recommendations. Samples were sequenced using the Illumina HiSeq 2000 platform to generate 100-bp paired-end reads.
Multi-IHC
To evaluate the density of the cell composition of TME and their relative spatial positioning in tumors, formalin-fixed paraffin-embedded (FFPE) slides from 5 NPC primary tumors among the cohort of 19 NPC patients with scRNA-seq were subjected to multi-IHC and multispectral imaging using the PANO Multiplex IHC kit (Panovue) to examine specific cell markers including CD3 (Abcam, Cat# SP7), CD68 (ZSGB-Bio, Cat# ZM0060), CD19 (CST, Cat# D4V4B), CD117 (CST, Cat# D3W6Y), α-SMA (Abcam, Cat# 1A4), Pan-CK (CST, Cat# C11). After each primary antibody was sequentially applied, the slides were incubated with secondary antibodies, followed by tyramide signal amplification (TSA). Next, the slides were subjected to microwave heat-treated antigen retrieval. Nuclei were stained with DAPI after all of the antigens had been labeled. To obtain multispectral images, the stained slides were scanned using the Mantra System (PerkinElmer), which captured the fluorescence excitation spectrum at 20-nm wavelength intervals (420–720 nm) within the same exposure time. Multiple scans were combined to build a single stack image. The spectrum of auto-fluorescence of the tissues and each fluorescein was extracted from the images of unstained and single-stained sections to establish a spectral library required for multispectral unmixing by InForm image analysis software (PerkinElmer). Using this spectral library, the reconstructed images of sections were obtained with the auto-fluorescence removed.
IF and flow cytometry
NPC xenograft C1740 and NPC primary biopsies were obtained from SYSUCC for IF staining and flow cytometry analysis. In brief, the 4-μm OTC-embedded frozen NPC specimens were blocked in 5% BSA and incubated with an anti-HLA-DRB1 antibody (Abcam, Cat# EPR6148) and CK-pan (Zhongshan Biotechnology, Cat# ab16669) at 4 °C overnight, after which they were counterstained with DAPI (Sigma-ALDRICH, Cat# D9524). Images were captured using an Olympus FV1000 confocal system (Olympus). For flow cytometry, NPC tissues were dissociated as described above. The single-cell suspension was stained with anti-EpCAM (Abcam, Cat# ab112068) and anti-HLA-DR (BD Pharmingen, Cat# 560651). Flow cytometry was performed on MoFlo Astrios, and the results were analyzed using FlowJo version 10.2.
IHC and immunoreactivity scoring
FFPE NPC specimens were collected at SYSUCC. All NPC patients were clinically diagnosed prior to radiotherapy or chemotherapy in the period from 2008 to 2010. The follow-up time for survivors was from 9 to 112 months (median 74.17 months). The clinicopathological parameters of these patients were summarized in Supplementary information, Table S6. The 4-μm FFPE sections were boiled in Citrate Antigen Retrieval Solution (pH 6.0) for 2.5 min in a microwave, after which they were incubated with the HLA-DR antibody (diluted at 1:600, Abcam, Cat# ab92511) followed by the secondary antibody for 30 min at 37 °C in a wet chamber. Next, the sections were stained with 3,3′-diaminobenzidine for 2 min and counterstained with Mayer’s hematoxylin to stain nuclei. Finally, the sections were dehydrated and mounted. Immunoreactivity was scored by two independent pathologists blinded to the clinical characteristics of the NPC patients. The intensity of the color reaction of tumor cells was scored as follows: no staining, 0; weak staining, 1; moderate staining, 2; strong staining, 3. The percentage of stained tumor cells was scored as follows: 0%, 0; 1%–10%, 1; 11%–50%, 2; 51%–80%, 3; 81%–100%, 4. The average of the values from the two referees was used as the final score. The IHC score was then generated as follows: intensity score × percentage score. All NPC patients were divided into high and low expression subgroups according to the median score of the HLA-DR immunostaining in tumor cells.
CCK-8 assay and tumor growth assay
To measure cell viability levels, CCK-8 assays (Beyotime, Cat# C0038) were performed. EpCAM+HLA-DRhi and EpCAM+HLA-DRlow C17 tumor cells were plated on collagen-treated 96-well plates at a density of 1 × 104 in sextuplicate and grown for 6 days. On day 6, 20 µL CCK-8 was added to each well and incubated for 4 h. The optical density (OD) values of all samples were detected using a microplate reader at a wavelength of 450 nm.
Female BALB/c nude mice (4–6 weeks, n = 12) were purchased from GemPharmatech and maintained in microisolator cages. The animals were maintained under protocols approved by the China Care Committee Institute. All 12 mice were randomly assigned to two groups and underwent subcutaneous injection of 100 μL of a viable cell suspension mixture (3 × 106) containing a suspension of 62% EpCAM+HLA-DRhi or EpCAM+HLA-DRlow C17 tumor cells and a solution of 31% matrigel and 7% collagen I (Sigma-ALDRICH, Cat# C3867). When the tumors could be touched, the size of each tumor was measured daily using callipers. The tumor volume was calculated using a simplified formula: 0.5 × length × width2. All mice were sacrificed on day 36 after the injection. Individual tumors were weighed and embedded in 10% paraffin. HLA-DR expression was assessed in each tissue sample by IHC as described previously.
Expression of co-inhibitory receptors on TILs from NPC tissues
For flow cytometry detection, additional NPC tissues (n = 27) were dissociated into single-cell suspensions as described above. Single-cell suspensions of each NPC tissue were subsequently divided evenly into two halves, with one half being used to detect the expression of co-inhibitory receptors on TILs and the other half being used to detect the abundance of EpCAM+HLA-DRhi cells.
To detect the expression of inhibitory receptors, single-cell suspensions were stained with antibodies against CD3 (Cat# 300440), PD-1 (Cat# 367430), Tim-3 (Cat# 345014), PE anti-human LAG-3 (Cat# 369206) and Tim-4 (Cat# 354008) (obtained from BioLegend), as well as antibodies against CD8 (Cat# 557834), CD276 (Cat# 565829), and CD4 (Cat# 742732) (obtained from BD Pharmingen). To detect the abundance of EpCAM+HLA-DRhi cells, single-cell suspensions were stained with anti-EpCAM (Abcam, Cat# ab112068) and anti-HLA-DR (BD Pharmingen, Cat# 560651). Then we correlated the expression of co-inhibitory receptors on TILs with the abundance of IS-high (EpCAM+HLA-DRhi) tumor cells in the same NPC tissues using FACS. All assays were performed on CytoFLEX S (Beckman Coulter). The data were analyzed with FlowJo and GraphPad Prism 8.3.0 software.
Tumor cell preparation and in vitro T cell expansion for co-culture experiment
TW03-(EBV+) tumor cells were trypsinised and resuspended in RPMI-1640 medium as described above. The single-cell suspensions were stained with antibodies against HLA-DR and EpCAM for FACS using a MoFlo Astrios. The EpCAM+HLA-DRhi and EpCAM+HLA-DRlow cells were enriched by FACS as described above. We chose NPC cell lines for the co-culture experiment because tumor cells from fresh NPC biopsies could not survive after 7–14 days.
Additional NPC tumor tissues were collected and dissociated into single-cell suspensions as described above. Single cells were suspended in X-VIVO 15 medium (Lonza, Cat# 04–418Q) at a density of 2 × 106/mL. Due to the limited number of T cells obtained from fresh NPC biopsies, the TILs have to be expanded to get enough cell numbers to perform the co-culture experiments.22,23
TILs were expanded by culturing in X-VIVO 15 medium with penicillin, streptomycin and 240 IU/mL rhIL-2 (Stemcell Technologies, Cat# 78036.2). Every 3 days, fresh medium with rhIL-2 was added to the culture. Next, TILs were detected based on human MHC class I molecule HLA-A2 (eBioscience, Cat# 12–9876–42) using flow cytometry. Only HLA-A2+ NPC (n = 3) TILs (with matched MHC I subtyping of TW03-EBV+) were further expanded for an additional 7–14 days before they were co-cultured with Epcam+HLA-DRhi and Epcam+HLA-DRlow TW03-(EBV+) tumor cells.
Co-culture and IFN-γ production by TILs measured by ELISPOT
In the co-culture experiment measuring IFN-γ produced by TILs, TILs were suspended in X-VIVO 15 medium at a density of 0.5 × 106/mL and co-cultured with EpCAM+HLA-DRhi and EpCAM+HLA-DRlow tumor cells at the indicated TILs:Tumor cells ratio (100:1, 50:1, or 20:1) for 6 h using the precoated BD™ Human IFN-γ ELISPOT Set (BD Pharmingen, Cat# 551849; 100 μL/well, 37 °C, 5% CO2). After washing, each plate was incubated with biotinylated detection antibodies followed by Streptavidin-HRP (Sangon Biotech, Cat# D111054–0100). AEC substrate (Solarbio, Cat# A2010) was added to the wells for spot development, and the developing reaction was stopped by washing the wells with deionized water. The plate was air-dried at room temperature, and the IFN-γ-producing cells were enumerated using an ImmunoSpot S6 Analyzer (Cellular Technology Ltd.) according to the manufacturer’s instructions. The result shown in Fig. 6e is the mean of triplicate well readings.
Co-culture and expression of co-inhibitory receptors on TILs
In the co-culture experiment to detect the expression of co-inhibitory receptors on TILs, TILs were suspended at a density of 5 × 105/well with 5 × 103/well of IS-high (EpCAM+HLA-DRhi) or IS-low (EpCAM+HLA-DRlow) tumor cells in VIVO-15 medium and low-dose rhIL-2 (240 IU/mL) in 48-well plates. The experiment was then performed by incubation for 48 h at 37 °C in a 5% CO2 atmosphere. After co-culturing, using the antibodies listed above (CD3, CD4, EpCAM, HLA-DR, CD8, PD-1, Tim-3, LAG-3, Tim-4 and CD276), we detected the expression of co-inhibitory receptors on TILs again using CytoFLEX S and analyzed by FlowJo V10.2 software.
Processing of RNA-seq data (Smart-seq2)
To profile host and EBV gene expression simultaneously, we constructed a hybrid reference genome containing both human (UCSC hg19) and EBV (NCBI NC_007605.1) reference sequences. Paired-end reads from each single cell were aligned to the human-EBV hybrid genome using Bowtie 2 with default parameters.41 Reads mapped to the human reference genome were used to quantify the gene expression levels of host genes. We initially used RSEM (version 1.3.0) to calculate the transcript-per-million (TPM) value of each gene, which was transformed as follows: Ei,j = log2(TPMi,j + 1).42 Here, TPMi,j refers to the TPM of gene i in cell j. Within each tumor, we defined genes with TPM > 1 as expressed genes and filtered cells with expressed gene < 2000. Meanwhile, we calculated a housekeeping gene score (HKGS) for each cell based on a previously defined gene list and filtered cells with HKGS < 3.5.21 For the remaining cells, we calculated the aggregate expression Ea of each gene, where Ea = log2(average(TPM1…k) + 1). After this procedure, we excluded genes with Ea < 4. Finally, we calculated the relative expression value Er of each gene as follows: Eri,j = Ei,j – average(Ei,1…n). Reads mapped to the EBV genome were retrieved to quantify the viral gene expression levels of the virus using Cufflinks.43 To attenuate the influence of any overlapping open reading frames of EBV genes on gene expression quantification, we used gene-coding sequence (CDS) regions to define the transcripts of EBV genes in this study.
Processing of RNA-seq data (10× Genomics)
scRNA-seq data generated from the 10× Genomics platform were processed using CellRanger (version 2.1.0). Briefly, we first used ‘CellRanger mkfastq’ to demultiplex the raw base call (BCL) files into FASTQ files. Next, ‘CellRanger count’ was used to perform alignment and quantify the gene expression levels of single cells via barcode recognition and UMI counting. Within each tumor, we first removed genes without expression across all cells. Next, we defined genes with UMI > 1 as expressed genes and filtered cells with <700 expressed genes. For the remaining cells, we calculated a TPM-like value for each gene by dividing the UMI counts by the sum of the UMI counts in that cell and multiplying by 10,000. The final expression value E was computed in the form of log2(TPM + 1). We also calculated the relative expression level for each gene in the form of Eri,j = Ei,j – average(Ei,1…n). To investigate different types of nonmalignant cells in the TME of NPC, we merged cells from different tumors using the ‘CellRanger aggr’ pipeline, followed by normalization by equalizing the read depths of different libraries. The output was converted to a Seurat object using the R Seurat package (version 2.1.0) for further analyses.44
Inferring CNV based on scRNA-seq data
To accurately distinguish malignant and nonmalignant cells, we inferred the CNVs of single cells based on scRNA-seq data (both Smart-seq2 and 10× Genomics). We adopted a previously described sliding-average strategy to normalize specific gene expression patterns and infer CNVs that reflected the genomic state of each cell.45 Briefly, we initially ordered genes according to their genomic positions (first from chromosome 1 to X and then by gene start position). After this process, we applied a 100-gene-sliding-average to the relative expression values to generate initial CNVs. The following equation was applied for the initial CNV calculation:
Here, CNVn(i) refers to the initial CNV (iniCNV) of cell n at gene i. Ern(oj) refers to the relative expression value of gene j in cell n. For the Smart-seq2 data, we defined Ei,j = log2(TPMi,j/10 + 1) to achieve better visualization (only in the CNV analysis). To attenuate the possible influence of any particular gene with extremely high or low relative expression levels on the sliding-average normalization, we adjusted all relative expression values greater than 3 to 3, whereas relative expression values less than −3 were adjusted to −3. The sliding average was calculated within each chromosome, with the exceptions of chromosomes 13, 18 and 21, in which the number of expressed genes was fewer than 100. For these three chromosomes, we extended the sliding windows to cover the initial and final 50 genes on their adjacent chromosomes. To further normalize the initial CNVs, we defined multiple baselines by choosing at least two different types of nonmalignant cells as controls. Different types of nonmalignant cells were classified based on the expression of various marker genes as previously described.21 Each 100-gene window had a maximal (Max_base) and minimal (Min_base) baseline. The final normalized CNVs (Smart-seq2) were defined as follows:
The final normalized CNVs (10× Genomics) were defined as follows:
Inferring CNV based on low-pass whole genome sequencing
Paired-end reads from low-pass whole genome sequencing were mapped to human reference genome hg19 (UCSC) using BWA with default parameters.46 We removed PCR duplicates using ‘Samtools rmdup’ followed by calculating the coverage depth at each covered base using ‘Samtools depth’. We segmented the whole genome into small windows (0.5 Mb in size) and calculated the total depth of each window. The total depth of each window was further normalized by the sequencing data volume. Using Loess normalization, we corrected the bias from the genomic GC content and calculated depth ratios across the whole genome of each tumor sample using the total depth of white blood cell samples as a control. The circular binary segmentation (CBS) algorithm documented in the R DNACopy package was used to merge windows with similar depth ratios into genomic segments. Adjacent segments were further joined using MergeLevels.47
Clustering of nonmalignant cells
We merged the 10× Genomics results of different tumors using the ‘CellRanger aggr’ pipeline, followed by normalization by equalizing the read depth of different libraries. The output was converted to a Seurat object using the R Seurat package (version 2.1.0). We excluded cells with <500 detected genes and genes expressed in <10 cells. The expression matrix was then log-normalized using the ‘NormalizeData’ function. Variably expressed genes were identified as having an average expression between 0.02 and 4 and dispersion greater than 0.2. The expression matrix was scaled by regressing the expression matrix against total UMI counts, cell-cycle scores, mitochondrial read counts and library IDs using the ‘ScaleData’ function. Here, we calculated a cell-cycle G1/S phase score and G2/M score to eliminate cell-cycle effects. To reduce dimensionality, variably expressed genes were used for the principal component analysis (PCA). The statistical significance of the PCA scores was determined using the ‘JackStraw’ function, and the first 10 principle components were used for t-SNE using the ‘RunTSNE’ function. Cell clusters were identified with a resolution of 0.5 using the ‘FindClusters’ function. Cells in the t-SNE graph were annotated to different cell types according to the expression of canonical markers. A group of cells that was located between T cell and B cell clusters in the t-SNE projection and expressed both T cell and B cell marker genes was excluded from the subsequent analysis because this group was most likely doublets or resulted from a high level of ambient RNA in the droplets.
Deciphering intratumor expression programs and meta-programs of NPC
We used a non-negative factorization algorithm (documented by the R NMF package)48 to identify underlying intratumor expression programs within the 10 tumors with the largest numbers of malignant cells. For each tumor, we applied NMF to the relative expression matrix (including Smart-seq2 and 10× Genomics) with all negative values replaced by zero. For the expression matrix from Smart-seq2, we excluded genes with a standard deviation of expression <0.8 within each tumor. For the expression matrix from 10× Genomics, we filtered genes with standard deviations of expression <0.5 within each tumor. We successfully extracted five potential programs from each tumor, which generated 50 intratumor expression programs among the 10 tumors. To investigate common programs among the 50 signatures, we defined the cell scores (CSs) of each program among the 10 tumors and calculated the Pearson correlation coefficient of these programs, based on which they were clustered into meta-programs. Two prevalent meta-programs, namely, cell cycle and immune response, were further analyzed.
Cell cycle analysis
We investigated the cell cycle status of both malignant and nonmalignant cells based on a previously defined gene list containing 43 G1/S genes and 54 G2/M genes.21 The expression patterns of these cell cycle-related genes were profiled among single cells in each tumor. To further assess cycling and noncycling cells, we calculated the average expression values of both G1/S and G2/M genes (G1/S and G2/M score) and conducted a t-test-based statistical analysis. Cells with either a G1/S score or G2/M score at least two-fold higher than the average of all cells and a P-value < 0.01 were considered cycling cells and were assigned to the G1 phase or G2/M phase. Cells with G1/S and G2/M scores at least two-fold higher than the average of all cells and a P-value < 0.01 were assigned to the S phase. We found that cells in noncycling status, G1 phase, S phase and G2/M phase formed an approximate circle.
CS calculation
CSs reflect the average expression levels of lists of genes in single cells. We calculated the CSs of certain gene sets by considering both average expression and the influence caused by different library complexities. As described by previous studies, we defined a control gene set in the calculation of different CSs.49 Briefly, we first partitioned genes into 25 bins according to their average expression levels across all cells. Then, for each gene from the target gene set (Gt), we randomly selected 100 genes from the bin to which this gene belonged. These randomly selected genes comprised the control gene set (Gc). Finally, CSs were calculated as follows: average (Gt) – average (Gc). Here, we used relative expression values to calculate CS. The CS of 140 bulk samples were defined by calculating the average expression levels of gene sets.
Immune program-related gradient
We defined the immune meta-program using 36 selected genes. To avoid random selection of genes to define the immune meta-program, we first calculated the average CSs of the 9 intra-tumor immune programs among all tumor cells. Next, we ranked genes in the 9 intra-tumor immune programs by their correlations with the average CSs. We selected the top 50 genes and excluded those that appeared in fewer than 3 intra-tumor immune programs to generate a 36-gene immune meta-program. To test the significance of the gradient, we randomly selected sets of 36 genes as control gene sets (the same size as the immune meta-program), which were then used to calculate CSs. The process was repeated 100 times in each tumor, and we compared the standard deviation of the immune gradient with that of the control gene sets as described in a previous study.21 In addition, the epithelial score was calculated based on the expression levels of genes, including KRT14, KRT17, KRT6A, KRT5, KRT19, KRT8, KRT16, KRT18, KRT6B, KRT15, KRT6C, KRTCAP3, SFN and EPCAM.
Gene set enrichment analysis of genes correlated with IS
Gene set enrichment analysis (version 19.0.24) was performed in each tumor with default parameters except that the ‘metric for ranking genes’ was set as ‘Pearson’. By doing so, genes were ranked by their correlations with the ISs of tumor cells. Gene sets ‘H’, ‘C2’, ‘C5’, ‘C6’ and ‘C7’, which were documented in the Molecular Signatures Database, were used in this analysis.
Coverage of EBV-derived sequencing reads
Reads mapped to the EBV genome were retrieved from each cell, and the coverage depth was calculated using ‘Samtools depth’. The mean coverage in 100-bp genomic windows was calculated, normalized by the total EBV coverage depth in certain cells, and then multiplied by 1000. The Circos plot was applied to display the summed coverage of all cells from each tumor.
T cell subclustering and functional analysis
T cell clusters were extracted and integrated for subclustering analysis using the Seurat package (version 2.1.0). Variably expressed genes were identified as having an average expression between 0.1 and 4 and dispersion greater than 0.2. T cells from tumor sample NPC63 were excluded from further analysis due to an obvious batch effect. Subclusters of T cells were identified using the graph-based clustering approach implemented in the ‘FindClusters’ function. A resolution of 0.8 was used for subcluster determination. Each T cell subcluster was annotated according to DEGs. To depict the developmental trajectory of CD8+ T cells, the Monocle2 R package was applied to the expression profiles of the cell subtypes. Briefly, the expression profiles (Seurat objects) were converted to Monocle cell data sets by the ‘importCDS’ function. DEGs were tested among the previously defined subclusters of T cells using the ‘differentialGeneTest’ function. Putative trajectories were plotted using the ‘plot_cell_trajectory’ function. To assess the functional states of CD8+ T cells, several cytotoxicity-associated genes (NKG7, PRF1, GZMA, GZMB, GZMK, IFNG, CCL4 and CST7) and exhaustion-associated genes (LAG3, TIGIT, PDCD1, HAVCR2 and CTLA4) were used to calculate the cytotoxicity score and exhaustion score.
Subclustering of myeloid cells, fibroblasts and ECs
Myeloid cells, fibroblasts and ECs were extracted and integrated for subclustering analysis using the Seurat package (version 2.1.0). Variably expressed genes were identified as having an average expression between 0.1 and 4 and dispersion greater than 0.2. We used the Seurat package (version 2.1.0) to identify subclusters based on the graph-based clustering approach implemented in the ‘FindClusters’ function. A resolution of 0.6 was used for subcluster determination in each of the three cell types. Each subcluster was annotated according to DEGs. To depict the developmental trajectories of myeloid cells, macrophages and fibroblasts, we used the ‘RunDiffusion’ function to construct diffusion maps. The Monocle2 R package was applied to the expression data of fibroblasts. Briefly, the expression profiles (Seurat objects) were converted to Monocle cell datasets by the ‘importCDS’ function. DEGs were tested among the previously defined subclusters of fibroblasts using the ‘differentialGeneTest’ function. Putative trajectories were plotted using the ‘plot_cell_trajectory’ function.
Gene set variation analysis (GSVA)
Pathway enrichment analyses were performed using the GSVA package with default parameters. The 50 hallmark pathways used in this analysis are documented by the molecular signature database and implemented in the GSEABase package.
Processing of bulk RNA-seq data
We combined scRNA-seq and bulk RNA-seq data (140 NPC samples) to study the composition of the NPC TME. The bulk RNA-seq raw data of 113 samples50 were downloaded from the Gene Expression Omnibus under accession number GSE102349, along with data for 9 samples from Hu et al.,51 and 18 newly sequenced samples. Among the 140 samples, 112 had progression-free survival data and 105 had overall survival data. Paired-end reads from the bulk RNA-seq data were mapped to the human-EBV hybrid genome using TopHat (version 2.1.1) with default parameters.41 The Cufflinks (version 2.2.1) tool suite was used to quantify gene expression levels. Briefly, we applied Cuffquant to the BAM file of each sample to calculate gene and transcript expression levels. Next, the results for all samples were combined and normalized using Cuffnorm to generate the final expression matrix, which was used for further analyses.
Decryption of the TME composition of NPC
To resolve the TME composition of NPC, we first identified specific markers of different nonmalignant cells based on 10× Genomics data. We mainly focused on the 6 different nonmalignant cell types with the highest abundance: T cells, B cells, macrophages, mast cells, fibroblasts and ECs. Using the Loupe Cell Browser provided by 10× Genomics, we extracted the top 50 genes that were differentially expressed in certain cell types as candidate marker sets. We then excluded genes with average expression < 0.2 in each cell type from each candidate marker set. In addition, we manually reviewed the expression patterns of the candidate markers using the Loupe Cell Browser and removed those that were obviously expressed by other cell types. The final cell type-specific markers are listed in Supplementary information, Table S9. Using these markers, we deciphered the TME compositions of 140 NPC samples with bulk RNA-seq data. All 140 NPC samples were divided into 5 groups based on TME composition using k-means clustering. The relative abundance of each cell type was estimated based on the expression levels of marker genes.
Inferring tumor cell-specific expression
To calculate the ISs of tumor cells using bulk RNA-seq data, we inferred tumor cell-specific expression according to a previously described method.46 We performed a multiple linear regression to subtract immune expression from nonmalignant cells and acquire cancer cell-specific expression. Briefly, we used the average expression levels of cell type-specific genes to estimate the relative abundance (Ar(t)) of each cell type (both malignant and nonmalignant). For a certain gene g in bulk tumor i, both malignant and nonmalignant cells contribute to its relative expression level (log-transformed and centered, Er(i,g)). We used the estimated Ar(t) for a multiple linear regression seeking to approximate the Er(i,g):
T covers all major cell types in the TME of NPC, including malignant cells, to account for tumor purity in this regression. X(t,g) refers to a gene-specific and cell type-specific scaling factor, which minimizes the sum of squares of the residuals, R(i,g). We then considered the residuals as the inferred cancer cell-specific expression.
Cell–cell interactions between different cell types
We explored potential interactions between different cell types, especially between tumor cells and other cell types, in the TME by focusing on ligand–receptor interactions. A known list of ligand–receptor pairs was obtained from a previous study.52 Using this list, we investigated ligands and receptors that were expressed among different cell types. For any scenario in which ‘cell type A’ expressed a ligand whose corresponding receptor was expressed by ‘cell type B’, we considered it as a valid interacting event between cell types A and B. We focused on 10× Genomics data and used the Seurat normalized expression matrix for further analysis. We defined a ligand or receptor as expressed if its average expression value across certain types of cells was greater than 0.2. Valid ligand–receptor interactions between tumor cells and other cell types were counted and further divided into incoming and outgoing events. An incoming/outgoing event was defined as the occurrence of a tumor cell expressing a receptor/ligand whose interacting ligand/receptor was expressed by another cell type.
Investigating genes correlated with cellular abundance
The abundance of each cell type was defined according to the average expression levels of cell-specific marker genes in the bulk expression profiles. Correlations between genes and the abundance of certain cell types were calculated. We compared the expression level of each gene in the cell type with which it was correlated and others using scRNA-seq data. DEGs between two cell types were defined as those with log2-transformed expression ratios > 2 or < –2. We focused on genes that were highly correlated with the abundance of one cell type, but were differentially expressed in another cell type, because these genes could mediate interactions between the two cell types.
Analyzing selected ligand–receptor pairs between different cell types
To quantify the extent of ligand–receptor interactions between different cell types, we assessed interaction events based on their level and significance as described in a previous study.53 For a pair of investigated cell types, the level of interaction was defined as the product of the average expression levels of ligands in one cell type and the average expression levels of their corresponding receptors in the other cell type. To acquire the significance of a particular interaction, we conducted a permutation test by randomly shuffling the dataset of all cells 1000 times and generating a background distribution of interaction levels, based on which we calculated a P-value. Here, we required that any ligand or receptor was expressed by at least 5% of cells of a particular cell type. If the ligand/receptor did not meet this criterion then we considered the interaction insignificant even if the permutation test indicated that it was significant.
Data availability
The raw sequence data reported in this paper have been deposited in the Genome Sequence Archive of the BIG Data Center at the Beijing Institute of Genomics, Chinese Academy of Science, under accession number HRA000087 (accessible at http://bigd.big.ac.cn/gsa-human). Code is available from the corresponding author on reasonable request.
References
Wei, W. I. & Sham, J. S. T. Nasopharyngeal carcinoma. Lancet 365, 2041–2054 (2005).
Lin, D. C. et al. The genomic landscape of nasopharyngeal carcinoma. Nat. Genet. 46, 866–871 (2014).
Tsang, C. M. & Tsao, S. W. The role of Epstein-Barr virus infection in the pathogenesis of nasopharyngeal carcinoma. Virol. Sin. 30, 107–121 (2015).
Jha, H. C., Pei, Y. G. & Robertson, E. S. Epstein-Barr Virus: diseases linked to infection and transformation. Front. Microbiol. 7, 1602 (2016).
Young, L. S., Yap, L. F. & Murray, P. G. Epstein-Barr virus: more than 50 years old and still providing surprises. Nat. Rev. Cancer 16, 789–802 (2016).
Li, H. P. & Chang, Y. S. Epstein-Barr virus latent membrane protein 1: structure and functions. J. Biomed. Sci. 10, 490–504 (2003).
Morris, M. A., Dawson, C. W. & Young, L. S. Role of the Epstein-Barr virus-encoded latent membrane protein-1, LMP1, in the pathogenesis of nasopharyngeal carcinoma. Future Oncol. 5, 811–825 (2009).
Tsao, S. W., Tramoutanis, G., Dawson, C. W., Lo, A. K. F. & Huang, D. P. The significance of LMP1 expression in nasopharyngeal carcinoma. Semin. Cancer Biol. 12, 473–487 (2002).
Bei, J. X. et al. A genome-wide association study of nasopharyngeal carcinoma identifies three new susceptibility loci. Nat. Genet. 42, 599–603 (2010).
Cui, Q. et al. An extended genome-wide association study identifies novel susceptibility loci for nasopharyngeal carcinoma. Hum. Mol. Genet. 25, 3626–3634 (2016).
Bruce, J. P., Yip, K., Bratman, S. V., Ito, E. & Liu, F. F. Nasopharyngeal cancer: molecular landscape. J. Clin. Oncol. 33, 3346 (2015).
Dai, W., Zheng, H., Cheung, A. K. & Lung, M. L. Genetic and epigenetic landscape of nasopharyngeal carcinoma. Chin. Clin. Oncol. 5, 16 (2016).
Arvey, A. et al. An atlas of the Epstein-Barr virus transcriptome and epigenome reveals host-virus regulatory interactions. Cell Host Microbe 12, 233–245 (2012).
Zheng, H. et al. Whole-exome sequencing identifies multiple loss-of-function mutations of NF-kappa B pathway regulators in nasopharyngeal carcinoma. Proc. Natl. Acad. Sci. USA 113, 11283–11288 (2016).
Li, Y. Y. et al. Exome and genome sequencing of nasopharynx cancer identifies NF-kappaB pathway activating mutations. Nat. Commun. 8, 14121 (2017).
Weichselbaum, R. R. et al. An interferon-related gene signature for DNA damage resistance is a predictive marker for chemotherapy and radiation for breast cancer. Proc. Natl. Acad. Sci. USA 105, 18490–18495 (2008).
Gandhi, M. K. et al. Galectin-1 mediated suppression of Epstein-Barr virus-specific T-cell immunity in classic Hodgkin lymphoma. Blood 110, 1326–1329 (2007).
Ouaguia, L., Mrizak, D., Renaud, S., Morales, O. & Delhem, N. Control of the inflammatory response mechanisms mediated by natural and induced regulatory T-Cells in HCV-, HTLV-1-, and EBV-associated cancers. Mediators Inflamm. 2014, 564296 (2014).
Azizi, E. et al. Single-cell map of diverse immune phenotypes in the breast tumor microenvironment. Cell 174, 1293 (2018).
Lambrechts, D. et al. Phenotype molding of stromal cells in the lung tumor microenvironment. Nat. Med. 24, 1277 (2018).
Tirosh, I. et al. Dissecting the multicellular ecosystem of metastatic melanoma by single-cell RNA-seq. Science 352, 189–196 (2016).
He, J. et al. Ex vivo expansion of tumor-infiltrating lymphocytes from nasopharyngeal carcinoma patients for adoptive immunotherapy. Chin. J. Cancer 31, 287–294 (2012).
Itzhaki, O. et al. Establishment and large-scale expansion of minimally cultured “young” tumor infiltrating lymphocytes for adoptive transfer therapy. J. Immunother. 34, 212–220 (2011).
Ting, J. P. Y. & Trowsdale, J. Genetic control of MHC class II expression. Cell 109, S21–S33 (2002).
Wosen, J. E., Mukhopadhyay, D., Macaubas, C. & Mellins, E. D. Epithelial MHC class II expression and its role in antigen presentation in the gastrointestinal and respiratory tracts. Front. Immunol. 9, 2144 (2018).
Tyznik, A. J., Sun, J. C. & Bevan, M. J. The CD8 population in CD4-deficient mice is heavily contaminated with MHC class II-restricted T cells. J. Exp. Med. 199, 559–565 (2004).
Do, J. S. & Min, B. Differential requirements of MHC and of DCs for endogenous proliferation of different T-cell subsets in vivo. Proc. Natl. Acad. Sci. USA 106, 20394–20398 (2009).
Forero, A. et al. Expression of the MHC Class II pathway in triple-negative breast cancer tumor cells is associated with a good prognosis and infiltrating lymphocytes. Cancer Immunol. Res. 4, 390–399 (2016).
McCaw, T. R. et al. The expression of MHC class II molecules on murine breast tumors delays T-cell exhaustion, expands the T-cell repertoire, and slows tumor growth. Cancer Immunol. Immun. 68, 175–188 (2019).
Sconocchia, G. et al. HLA Class II A antigen expression in colorectal carcinoma tumors as a favorable prognostic marker. Neoplasia 16, 31–42 (2014).
Buetow, K. H. et al. High GILT Expression and an active and intact MHC Class II antigen presentation pathway are associated with improved survival in melanoma. J. Immunol. 203, 2577–2587 (2019).
Balko, J. M. et al. MHC-II expression to drive a unique pattern of adaptive resistance to antitumor immunity through receptor checkpoint engagement. J. Clin. Oncol. 36(5 suppl), 180 (2018).
Donia, M. et al. Aberrant expression of MHC Class II in melanoma attracts inflammatory tumor-specific CD4(+) T-Cells, which dampen CD8(+) T-cell antitumor reactivity. Cancer Res. 75, 3747–3759 (2015).
Chaoul, N. et al. Lack of MHC class II molecules favors CD8(+) T-cell infiltration into tumors associated with an increased control of tumor growth. Oncoimmunology 7, e1404213 (2018).
Chen, R. et al. ISG15 predicts poor prognosis and promotes cancer stem cell phenotype in nasopharyngeal carcinoma. Oncotarget 7, 16910–16922 (2016).
Snell, L. M., McGaha, T. L. & Brooks, D. G. Type I interferon in chronic virus infection and cancer. Trends Immunol. 38, 542–557 (2017).
Fang, W. F. et al. Camrelizumab (SHR-1210) alone or in combination with gemcitabine plus cisplatin for nasopharyngeal carcinoma: results from two single-arm, phase 1 trials. Lancet Oncol. 19, 1338–1350 (2018).
Peng, J. Y. et al. Single-cell RNA-seq highlights intra-tumoral heterogeneity and malignant progression in pancreatic ductal adenocarcinoma. Cell Res. 29, 725–738 (2019).
Picelli, S. et al. Full-length RNA-seq from single cells using Smart-seq2. Nat. Protoc. 9, 171–181 (2014).
Busson, P. et al. Establishment and characterization of three transplantable EBV-containing nasopharyngeal carcinomas. Int. J. Cancer 42, 599–606 (1988).
Langmead, B. & Salzberg, S. L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 9, 357–359 (2012).
Li, B. & Dewey, C. N. RSEM: accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinformatics 12, 323 (2011).
Trapnell, C. et al. Differential gene and transcript expression analysis of RNA-seq experiments with TopHat and Cufflinks. Nat. Protoc. 7, 562–578 (2012).
Butler, A., Hoffman, P., Smibert, P., Papalexi, E. & Satija, R. Integrating single-cell transcriptomic data across different conditions, technologies, and species. Nat. Biotechnol. 36, 411 (2018).
Patel, A. P. et al. Single-cell RNA-seq highlights intratumoral heterogeneity in primary glioblastoma. Science 344, 1396–1401 (2014).
Li, H. & Durbin, R. Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics 25, 1754–1760 (2009).
Willenbrock, H. & Fridlyand, J. A comparison study: applying segmentation to array CGH data for downstream analyses. Bioinformatics 21, 4084–4091 (2005).
Gaujoux, R. & Seoighe, C. A flexible R package for nonnegative matrix factorization. BMC Bioinformatics 11, 367 (2010).
Puram, S. V. et al. Single-cell transcriptomic analysis of primary and metastatic tumor ecosystems in head and neck cancer. Cell 171, 1611–1624 (2017).
Zhang, L. et al. Genomic analysis of nasopharyngeal carcinoma reveals TME-based subtypes. Mol. Cancer Res. 15, 1722–1732 (2017).
Hu, L. J. et al. Comprehensive profiling of EBV gene expression in nasopharyngeal carcinoma through paired-end transcriptome sequencing. Front. Med. 10, 61–75 (2016).
Ramilowski, J. A. et al. A draft network of ligand-receptor-mediated multicellular signalling in human. Nat. Commun. 6, 7866 (2015).
Vento-Tormo, R. et al. Single-cell reconstruction of the early maternal-fetal interface in humans. Nature 563, 347–353 (2018).
Acknowledgements
This work was financially supported by the National Key R&D Program (2017YFA0505604), the National Science and Technology Major Project (2019YFC1315702, 2018ZX10302205), the National Natural Science Foundation of China (31722003, 81520108022, 31770925, 81621004, 81830090, 81772883, 81772895, 81602371, and 81230045), Guangdong Province Key Research and Development Program (2019B020226002), Natural Science Foundation of Guangdong Province (2017A030312003), and Guangzhou Science Technology and Innovation Commission (201607020038). R.L. was supported by the Postdoctoral Fellowship of Bo Ya. We thank Fei Wang from the National Center for Protein Sciences Beijing (Peking University) and Shupeng Chen from SYSUCC for assistance with FACS. The authenticity of this article has been validated by uploading the key raw data onto the Research Data Deposit public platform (www.researchdata.org.cn), with the approval number RDDB2020000935.
Author information
Authors and Affiliations
Contributions
M.-S.Z., F.B., S.J., R.L., Q.Z., M.-Y.C., and C.Y. designed the experiments; R.L. and S.J. performed data analyses; S.J. and C.Y. performed experiments with assistance from Y.-M.L., Y. Zhao and Q.Z.; M.-Y.C., R.Y., H.-Q.M., G.-N.W., L.-Q.T., Q.-Y.C., J.-Y.P., F.H., J.L., J.W., L.Z., and J.-Y.P. provided clinical samples; Q.Z., Y.-M.L., Y.-L.L., J.-P.L., Y.-N.L., S.-X.L., Q.L., Y. Zhang, and T.-L.X. performed functional experiments; R.L. and S.J. wrote the manuscript, with feedback from M.-S.Z., F.B., Q.Z., B.E.G., B.Z., L.S.Y.; Q.Z., F.B., and M.-S.Z. supervised all aspects of this study.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Supplementary information
Rights and permissions
About this article

Cite this article
Jin, S., Li, R., Chen, MY. et al. Single-cell transcriptomic analysis defines the interplay between tumor cells, viral infection, and the microenvironment in nasopharyngeal carcinoma. Cell Res 30, 950–965 (2020). https://doi.org/10.1038/s41422-020-00402-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/s41422-020-00402-8
This article is cited by
-
Nasopharyngeal carcinoma: current views on the tumor microenvironment's impact on drug resistance and clinical outcomes
Molecular Cancer (2024)
-
T-cell infiltration and its regulatory mechanisms in cancers: insights at single-cell resolution
Journal of Experimental & Clinical Cancer Research (2024)
-
Single-cell transcriptomics reveals cell atlas and identifies cycling tumor cells responsible for recurrence in ameloblastoma
International Journal of Oral Science (2024)
-
Single-cell transcriptomic analyses of tumor microenvironment and molecular reprograming landscape of metastatic laryngeal squamous cell carcinoma
Communications Biology (2024)
-
A novel EIF3C-related CD8+ T-cell signature in predicting prognosis and immunotherapy response of nasopharyngeal carcinoma
Journal of Cancer Research and Clinical Oncology (2024)
